YOLO: The Revolutionary Real-Time Object Detection Algorithm Explained
The detection of objects is critical in autonomous driving, security systems, robotics applications, and many other fields. In the vast landscape of object detection algorithms, YOLO (You Only Look Once) is recognized as a revolutionary model for real-time object detection because of its exceptional speed and accuracy. This blog post aims to explain the fundamentals of YOLO and its impact in the field. The architecture of the algorithm, its prominent features, and the subsequent changes in algorithm improvements over different versions will be discussed in detail. At the end of the article, readers will deepen their understanding of how YOLO works and the reasons it is so popular for emerging technologies.
What is YOLO models and how does it work?
You Only Look Once (YOLO) is an algorithm for object detection that is unique in its ability to use deep learning for real-time analysis. YOLO works by dividing the image into a grid, estimating class probabilities, and predicting bounding boxes for objects in each grid cell simultaneously. Unlike older techniques that require several image scans, YOLO utilizes a convolutional neural network (CNN) to analyze the image in a single scan. This allows for incredible speed and efficiency while also maintaining accuracy levels. YOLO container architecture has changed dramatically throughout the years. With each new version, improvements in detection, performance, speed, and ease of use have been made in complex systems like self-driving cars and security devices.
Understanding the YOLO Algorithm
The approach of the YOLO (you only look once) algorithm is perhaps the most remarkable because it places all computer vision methods so far known to deal with object detection and recognition under the task of a single network – perceptually singular object localization and identification. An input image is split into a grid, subsequently each grid cell is assigned the object detection task along with estimating the bounding box and class probabilities. Traditional methods apply multiple-pass classification models over an image, whereas YOLO simplifies it by analyzing the entire image.
Another remarkable feature of YOLO is its real-time performance and ability to detect multiple objects accurately simultaneously. YOLO uses a single convolutional neural network (CNN), which predicts bounding boxes and class probabilities in a single pass. This architecture helps maintain the balance between speed and precision.
With the new technological advancements, YOLO has evolved into numerous versions, such as YOLOv3 and YOLOv4, the most recent being YOLOv5. Each iteration improves the model’s architecture, more sophisticated augmentation of training images, and better recognition of small objects, increasing its applications in fields like autonomous vehicles, facial recognition, medical imaging, and surveillance systems.
The algorithm’s efficiency and accuracy stem from its innovative design. It makes it less computationally expensive, faster, and more precise, making it ideal for real-time object detection, increasing the demand for the object detection system.
Key components of YOLO architecture
Real-time YOLO (You Only Look Once) object detection relies on numerous components. The significant parts of YOLO architecture include:
- Convolutional Neural Networks (CNNs)—YOLO utilizes CNNs to detect image spatial features. This includes splitting images into grids, where bounding boxes and class probabilities are estimated for each cell.
- Bounding Box Prediction—Each grid cell can predict a certain number of bounding boxes and their respective pixel coordinates, along with the width, height, and confidence score. This feature allows YOLO to detect numerous objects in a single image accurately.
- Class Prediction—YOLO predicts the class probability distribution for each bounding box, enabling objects to be accurately categorized and detected rapidly.
- Unified Detection Framework - Classification and localization processes are performed using a single neural network which is why YOLO is significantly more efficient and faster than conventional object detection techniques which relied on cascading neural networks to split the tasks above.
- Non-Maximum Suppression (NMS): The irrelevant and less accurate detections are filtered out using borders that overlap contours out of bounding boxes, guaranteeing that only the most reliable prediction boxes are validated.
The components and algorithm's design all contribute to YOLO's ability to achieve the speed, accuracy, and efficiency needed for real-time object detection.
Single-shot vs. Two-shot Object Detection
As the term suggests, single-shot object detection can undertake object recognition in a single forward pass. This indicates its ability to handle both the recognition of a given class and the ascertainment of its spatial location simultaneously. YOLO (You Only Look Once) and SSD (Single Shot MultiBox Detector) are algorithms that belong to this category. Due to a single-pass architecture, these methods are optimal for real-time implementations and excel in speed. However, to achieve high rates of speed, single-shot methods may sacrifice some accuracy, especially for small objects. This can be attributed to reliance on fewer feature scales or anchor boxes for prediction.
Two-shot object detection has two designs, and its detection processes are carried out in two stages, each providing a more comprehensive result. The first stage (Region Proposal Network) termed RPN, searches for regions of interest, where an object of a certain class might exist. The second stage classifies the ROIs and fine-tunes the objects' bounding boxes. Examples of such two-step procedures are Faster R-CNN and Mask R-CNN. These models are optimal for high accuracy but slow speed, meaning they can accurately detect and segment objects without requiring speed.
|
Parameter |
Single-shot (YOLO, SSD) |
Two-shot (Faster R-CNN, Mask R-CNN) |
|---|---|---|
|
Speed (FPS) |
~45-155 FPS (GPU-dependent) |
~5-30 FPS (GPU-dependent) |
|
Accuracy (mAP on COCO) |
40-50 (generalized for YOLOv4, SSD) |
50-60+ (with optimization) |
|
Use Case |
Real-time tasks like robotics, autonomous vehicles |
High-precision tasks like medical imaging |
|
Strengths |
Fast, efficient, end-to-end design |
Highly accurate, flexible for complex tasks |
|
Weaknesses |
Lower accuracy for small or overlapping objects |
Slower, computationally intensive |
Thus, the choice between single-shot and two-shot object detection depends on the application's requirements. Single-shot methods favor speed, while two-shot approaches prioritize accuracy.
How has YOLO evolved?
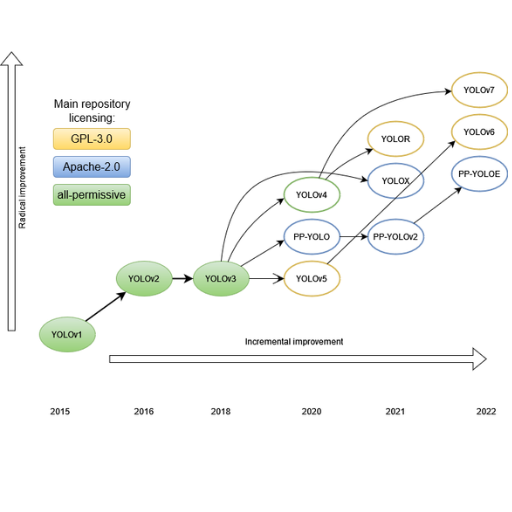
YOLO (You Only Look Once) has seen substantial changes throughout its lifecycle. While the original YOLO model provided a basic, complete object detection functionality, its main emphasis was speed and simplicity. When newer versions like YOLOv2 and YOLOv3 emerged, they were able to harness batch normalization, anchor boxes, and multi-scale prediction techniques to improve overall accuracy. YOLOv4 and YOLOv5 incorporated novel CSP (Cross Stage Partial) networks, mosaic augmentation, and auto-learning bounding box anchors to optimize performance further. The latest versions of YOLO, including YOLOv7, have sought to improve detection features and efficiency in modern computers to expand their application range. This evolution has catered to the speed and accuracy of detection systems towards specific use-case scenarios.
The original YOLO and its limitations
The initial YOLO (You Only Look Once) model fundamentally transformed object detection by treating it as a single regression problem, utilizing a much faster approach than before. This model had some gaps, however. Detection of small objects proved problematic, especially when they were spatially constrained within the same grid cell. Furthermore, its accuracy was lower than other architectures, including complex scenarios with high clutter compared to Faster R-CNN. Additionally, the lack of detail in the architecture, which enabled faster performance, made it challenging to capture complex scenes with multiple variances. To overcome these challenges, improved versions were developed, which was made possible by increased YOLO iterations.
Improvements in subsequent YOLO versions
Each later version of YOLO implements new features to eliminate limitations observed in previous iterations. For example, YOLOv2 incorporated anchor boxes, batch normalization, multi-res classifier, and Darknet-19 backbone to improve the accuracy of detecting objects and better manage multi-scale objects. Darknet-19 was a favorable addition due to its offered speed and performance. To improve accuracy even further, YOLOv3 utilized a multi-scale feature map approach with precision obtained through FPN (Feature Pyramid Networks). Darknet-53 was also added to enhance the scale and strength of feature extraction.
Further optimization of speed and accuracy performance were the two focuses of YOLOv4 and YOLOv5. Its performance with larger datasets was also boosted through augmenting Weighted Residual Connections (WRC), Cross Stage Partial connections, CSPDarknet53, and the SPP module (Spatial Pyramid Pooling) support. Structurally, YOLOv5 moved toward a more lightweight build, increasing ease for real-world employment and faster inference.
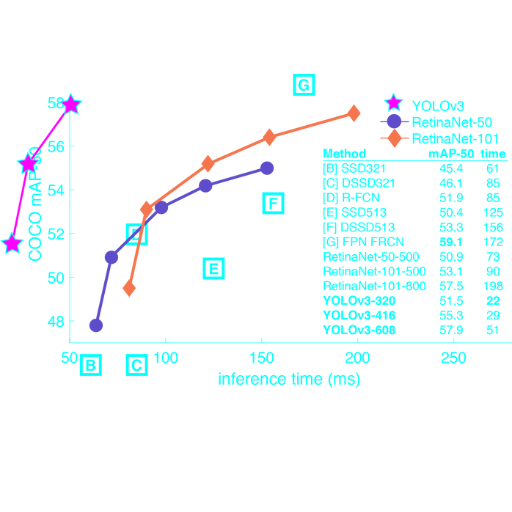
Fundamentally changed parameters are larger set input resolution, better mAP (mean Average Precision) numbers with tests, and quicker response times. The difference in the dataset's map is noteworthy: Under the same computational conditions, COCO is at 57.9% for YOLOv3 and 65.7% for YOLOv4. These advancements shifted the AI community's focus to YOLO as the best object detection framework available in real time.
Latest advancements: YOLO v7 and beyond
We have seen remarkable improvement in efficiency and accuracy with YOLOv7. This release adds an optimized model architecture and better model scaling, improving both speed and prediction accuracy. Its ability to achieve state-of-the-art performance on various benchmarks at significantly low cost opens up the technology for real-time applications. Advanced techniques such as model reparameterization and task alignment are also incorporated in YOLOv7, making this a valuable version for self-driving cars and medical imaging. In this context, research and development has not stopped and targets even lower sustainability and higher performance in computer vision tasks.
What makes YOLO stand out among object detection methods?
YOLO differs from other object detection techniques due to its impressive speed and accuracy. It analyzes images as they are being captured, which increases the efficiency of completing time-sensitive tasks. It makes the detection task easier because of its single, unified architecture that enforces the classification and localization of the object in a single neural network. Furthermore, YOLO’s adaptability across domains such as security and healthcare showcases its reliability and robustness.
Speed and accuracy balance in YOLO
YOLO's design and optimization methods allow the model to balance both speed and accuracy intelligently. Using a single convolutional neural network to predict bounding boxes and class probabilities concurrently is a vast advantage that cuts down on computation costs in YOLO. YOLOv4 and YOLOv5, for example, incorporate CSPNet and SPP, which further improve the balance, allowing the models to achieve high accuracy and fast inference speeds. Important technical specs include an average inference time of 5-8 milliseconds per frame on modern GPUs such as the NVIDIA RTX 30 series and a mean average precision of 50-65% on the COCO dataset, which is quite common. Those parameters speak for themselves in highlighting the efficiency of YOLO as a real-time object detection model with high-speed performance statistics.
Comparing YOLO to other detection algorithms
My analysis indicates that YOLO performs exceptionally well compared to other detection algorithms like SSD and Faster R-CNN due to its speed and accuracy. For instance, SSD requires multiple processing stages to achieve its results. However, YOLO achieves higher inference speeds because it processes the entire image in one evaluation. Similarly, compared to Faster R-CNN, which is more precise but slower in other areas, YOLO has much greater speed and efficiency for real-time needs. This dynamic balance between speed and accuracy rationalizes its use in systems that require rapid decision-making, such as autonomous robotic systems and video analysis.
Real-time capabilities of YOLO models
The speed Achieved in YOLO (You Only Look Once) models comes from processing images with a single pass through a single neural network. Instead of splitting an image into separate regions and processing them separately, YOLO employs a grid system that scans the image for multiple objects simultaneously. This simple and innovative technique bestows YOLO with staggering image guessing speeds, crystalizing its suitability for time-constrained operations.
This is to say, the sooner the guesses are made, the better! Models such as YOLOv3 and YOLOv4 process up to 45 frames per second (fps) on modern GPUs, while the new YOLOv5 and YOLOv8 models may exceed 100 fps based on hardware and configuration. Consideration of some technical parameters responsible for these astounding real-time capabilities are:
- Model Size: Smaller models (like YOLOv5n, YOLOv8n) with lighter weights for example trade off speed with accuracy which is favorable for real-time operations.
- Input Resolution: Moderately lower quantifications such as 416x416 or 640x640 resolutions for real-time applications have relatively good accuracy with lesser processing time.
- Batch Size: Regarding inference speed for real-time applications, using a batch size of 1 is optimum.
- Hardware Optimization: Parallel computations further enhances the performance of YOLO with use of high-end PCs GPUs (e.g. NVIDIA RTX series) or use of AI accelerators such as TensorRT and ONNX.
The abilities above enable instantaneous decision-making, making YOLO the preferred selection for self-driving cars, drone supervision, and video monitoring.
How do we implement YOLO for object detection tasks?
I set up the environment for object detection that utilizes YOLO, most likely in Python, using PyTorch or TensorFlow. My next step is to prepare my dataset, ensuring it is annotated in a compatible format, e.g., YOLO or COCO. I then constitute the model by training it on my dataset, or for more simplistic use cases; I can leverage the pre-trained model directly for inference. I can use OpenCV and other custom libraries to perform real-time object detection using video or still images as input. At the same time, the model provides outputs in bounding boxes with class labels and corresponding confidence scores. The implementation is efficient and scalable as long as the hardware is optimized correctly (for example, a GPU is being used).
Setting up YOLO for computer vision projects
When applying YOLO for my computer vision projects, I always start with selecting the version that aligns with the project requirements; more often than not, I prefer either YOLOv5 or YOLOv8 versions due to their popularity and overall performance. I download the model weights for the pre-trained model while also setting up my development environment with required packages like Python, PyTorch, and OpenCV. Following this, I get or prepare a labeled dataset and make sure to include enough COCO format-supporting datasets with good-quality annotations. I customize the YOLO training scripts at this stage and modify parameters such as batch size, learning rate, and classes assigned to the given case. After the model is trained or fine-tuned on the dataset, I validate its performance by testing the model against new data. For deploying, integrating the YOLO model into a practical use case uses frameworks like Flask or Tensorflow Lite while always focusing on optimization concerning the desired accuracy and speed for the given hardware, whether GPU or edge devices.
Training YOLO on custom datasets
Steps to train YOLO on custom datasets consist of:
- Dataset Preparation
- Format: YOLO needs the dataset in its format, which means having images and corresponding .txt annotation files. Annotations can be easily made on LabelImg or Roboflow.
- Classes File: Make classes.names file containing all of the class names, with each line being new.
- Dataset Split: Split the dataset into training (70-80%) and validation (20-30%) datasets.
- Configuration Adjustments
- Change the data.yaml or .cfg file to the configuration and number of classes (nc) you have in your dataset.
- Change the file locations for the training and validation datasets and their respective locations.
- Training Parameters
Always use a good weight file that is pre-trained; for example, Yolo 5 uses yolov5s.pt file, while Yolo 8 has yolov8n.pt. Set the following parameters for training:
- Batch size (batch): It is usually between 16-64 or more, depending on how much memory the GPU has.
- Learning Rate (lr0): Start with 0.01, but it can change depending on the learning curve.
- Epoch (epochs): Courser datasets range from 100 to 300.
- Img_size: Set it to 640 for most standard setups; go with 1280 if you want more accuracy.
- Hardware Considerations:
- GPU Setup: Modern hardware facilitates the training, so GPU like NVIDIA RTX 3060 or newer will aid in training.
- TensorRT or TensorFlow Lite can optimize inference if deployed on edge devices.
- Model Validation
- To confirm the model effectiveness, check its precision, recall, and compute the mean average precision (mAP) scores on the validation set.
With these steps and adequate tuning of parameters to fit your dataset and hardware specifications, you can train a consistently accurate YOLO model.
Optimizing YOLO Performance for Specific Use Cases
To optimize YOLO for specific use cases, it is necessary to pay attention to the task nature, dataset, and deployment context.
- Dataset Customization:
- Focus your dataset on the specific use case by acquiring high-quality images that portray all possible variations of the objects. Use LabelImg or Roboflow for image segmentation during the fine-tuning phase.
- Avoid bias within the dataset. For instance, training a custom YOLOv5 model aimed at vehicle detection covers different types of vehicles from different angles and in various environments.
- Anchor Box Optimization:
- Applying k-means clustering to determine the most suitable anchor box dimensions for a given object size in your dataset. This will reduce prediction errors.
- Add custom anchors to the YOLO configuration file. For YOLOv4/Y0LOv5, custom anchors can be added when the model is being trained using the—- image-size and—-auto anchor flags.
- Model Pruning and Quantization:
- Pruning reduces a model's size and associated computation requirements by removing unnecessary layers or parameters. SparseML provides structural pruning specifically for YOLO models, enabling easier pruning.
- Edge devices benefit from reduced computation (e.g., INT8 quantization) without significant drops in accuracy. This can be done using TensorRT or ONNX Runtime.
- Tuning of Hyperparameters
- Modulate the learning rates (--lr), batch size (--batch-size), and momentum values according to what your hardware can handle.
- For example, parameters for YOLOv5 with an adequate balanced dataset and decent hardware (RTX 3080) would be:
- lr0=0.01, momentum=0.937, batch-size=16.
- Conduct parameter sweeps with the aid of Weights & Biases (WandB).
- Image and Data Augmentation
- To increase model generalization, employ techniques such as mosaic augmentation, random flips, and changes in color space. To increase the amount of augmentation applied, change the YOLO augmentation parameters.
- Inference Optimization
- For deployment, use TensorRT or OpenVINO. Change the model to ONNX and optimize it for your device. For instance:
- NVIDIA GPUs work well with INT8 quantization.
- Edge devices with a balance between performance and accuracy prefer FP16.
With these implementations and configurations tailored to specific use cases, the performance of YOLO models on real-world tasks can be robust.
What are the applications of YOLO in various industries?
The functionality of YOLO (You Only Look Once) in real-time object detection seamlessly serves many industries.
- Retail and Inventory Management: YOLO is utilized for stock counting, product placement recognition, and even shoplifting through video information systems.
- Healthcare: In medical imaging, it assists in detecting abnormalities such as tumors in X-rays and MRIs with great precision.
- Autonomous Vehicles: YOLO enables a system to perceive the environment safely by identifying pedestrians, vehicles, and obstacles.
- Security and Surveillance: To increase security, it is used for face recognition, unauthorized area intrusion alarms, and restricted access area monitoring.
- Agriculture: Farmers implement YOLO for crop monitoring, pest detection, and livestock behavior monitoring.
- Manufacturing: By observing the mechanism of the product assembly line, YOLO aids in quality control by detecting faults within the items.
Each instance demonstrates the contribution of patience and automation with improved accuracy and efficiency by the technology of YOLO.
YOLO in autonomous vehicles and robotics
You Only Look Once (YOLO) optimizes object detection and classification in robotics and autonomous vehicles, allowing simultaneous detection and tracking. I utilize YOLO’s precision and speed to recognize pedestrians, vehicles, traffic signs, and other obstacles of concern so that they may be avoided. Quick image processing also enables robots to perform precise movements, like grasping objects and avoiding collisions. Integrating YOLO enables me to design more adaptable and responsive systems for dynamic environments.
Security and surveillance using YOLO
YOLO significantly contributes to security and surveillance by allowing for the effective and rapid detection of threats in real-time. I apply YOLO to supervise video actively feeds in real-time to recognize people, vehicles, or anything suspicious with uncanny accuracy. Its performance is determined by technical parameters such as a fast inference time of 22-33 milliseconds per frame, high mAP scores, and multi-class processing capabilities. YOLO makes these systems more effective by providing the ability to detect objects in low-light conditions or dense crowds, ensuring that timely responses and situation awareness are further improved.
YOLO for medical imaging and diagnostics
YOLO has served as a powerful asset in medical imaging and diagnosis. I employ this tool to assist in diagnosing anomalies in medical scans like X-rays and MRI or CT images, making them more reliable and easier to interpret. His speed in detecting objects makes it possible to analyze vast amounts of information in real-time, which helps lessen the burden shouldered by the medical personnel while increasing accuracy. When applying the YOLO model, I train it on relevant datasets to detect critical conditions such as tumors, fractures, and several other critical conditions so that timely intervention can be instituted as early as possible. This approach not only improves the accuracy of diagnosis but also enhances patients' overall experience because it detects complex medical imagery.
References
- YOLO-LITE: A real-time object detection algorithm optimized for non-GPU computers - Discusses YOLO-LITE, a variant of YOLO optimized for non-GPU systems.
- YOLO with adaptive frame control for real-time object detection applications - Explores YOLO's applications in real-time object detection and potential challenges.
- A real-time object detection algorithm for video - Focuses on improvements to YOLO for video-based real-time object detection.
Frequently Asked Questions (FAQ)
Q: What is YOLO object detection, and how does it work?
A: YOLO (You Only Look Once) is a state-of-the-art object detection algorithm that uses a single neural network to predict bounding boxes and class probabilities for objects in images. It divides the image into a grid and predicts multiple bounding boxes and class probabilities for each grid cell, allowing fast and accurate real-time object detection.
Q: How has the evolution of YOLO improved object detection?
A: YOLO's evolution has significantly improved object detection. Each new version, from YOLOv1 to YOLOv7, has introduced enhancements in accuracy, speed, and efficiency. These improvements include better network architectures, advanced training techniques, and more sophisticated loss functions, resulting in more accurate and faster real-time object detectors.
Q: What are the key features of the YOLO object detection algorithm?
A: The YOLO object detection algorithm is known for its speed and accuracy. Key features include single-shot detection, which processes the entire image in one forward pass; grid-based prediction, allowing for multiple object detection; real-time processing capabilities; and the ability to learn generalizable representations of objects, making it effective across various applications.
Q: How does YOLO compare to other object detection algorithms?
A: YOLO generally outperforms many other object detection algorithms in terms of speed and accuracy. Compared to two-stage detectors like R-CNN, it offers a better balance between accuracy and real-time performance. YOLO's single-shot approach makes it faster than region proposal-based methods while maintaining competitive accuracy in object detection tasks.
Q: What are the applications of YOLO in real-time detection scenarios?
A: YOLO's real-time detection capabilities suit various applications, including autonomous vehicles, surveillance systems, robotics, and augmented reality. It's beneficial in quick object identification and localization scenarios, such as traffic monitoring, crowd analysis, and industrial quality control.
Q: How has the performance of object detection models improved with newer versions of YOLO?
A: The YOLO algorithm has significantly improved with each iteration. Newer versions have increased object detection accuracy while maintaining or even improving processing speed. For example, YOLOv7 offers enhanced performance in detecting small objects and handling complex scenes, surpassing previous YOLO versions and other state-of-the-art object detection models in accuracy and efficiency.
Q: What challenges does YOLO address in computer vision and object detection?
A: YOLO addresses several key challenges in computer vision and object detection. It solves the problem of real-time processing, which is crucial for applications like autonomous driving. YOLO also improves the accuracy-speed trade-off that is common in object detection algorithms. Additionally, it handles detecting multiple objects and classes within a single image more efficiently than many previous models.
Q: How does YOLO handle objects of different sizes and scales in images?
A: YOLO uses a multi-scale approach to handle objects of different sizes and scales. Using various anchor boxes, it employs feature pyramids and predicts objects at different scales. This allows the algorithm to detect both large and small objects effectively. Recent versions of YOLO have further improved this capability, enhancing the detection of objects across a wide range of sizes and scales.
Q: What are the limitations of YOLO in object detection?
A: While YOLO is highly effective, it does have some limitations. It can struggle with tiny objects or objects that appear in unusual contexts. The algorithm may also have difficulty when objects are very close or overlapping. Additionally, YOLO's accuracy can be slightly lower than that of some two-stage detectors in specific scenarios, though this gap has narrowed with recent versions.