YOLO Object Detection: Revolutionizing Real-Time Image Analysis
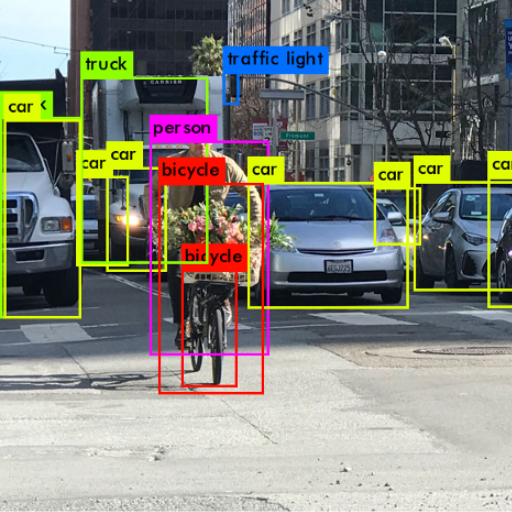
YOLO (you only look once) has turned out to be a revolutionary method of real-time image analysis through object detection. This blog offers a thoughtful examination of the YOLO framework including its basic features, benefits, and real-world uses. Initially, we will describe the basic components of YOLO including single-shot detection which allows efficient and effective rapid object identification. Subsequently, we will analyze the difference in performance delivered by the classical methods and YOLO concerning speed and accuracy. Lastly, the article will display practical applications of YOLO in changing different sectors like self-driving cars, retail, and security. After reading this post, you will be well knowledgeable of the significance of YOLO in the advancement of real-time image detection and its prospects.
What is YOLO and how does it work?
The term “YOLO,” meaning “You Only Look Once,” describes an advanced algorithm of object detection that processes the entire image in a single evaluation which transforms image analysis. Instead of working on multiple stages, YOLO uses a single neural network to split the image into grids and predict bounding boxes with class probabilities, all at the same time. Because of the unique method, YOLO can achieve speed and accuracy at impressive rates as it reduces redundancy by focusing on the most important features for object detection. Techniques such as anchor boxes as well as a non-max suppression allow YOLO to effectively and accurately identify and localize multiple objects in real-time which is suitable for dynamic real-world applications.
Understanding the YOLO algorithm
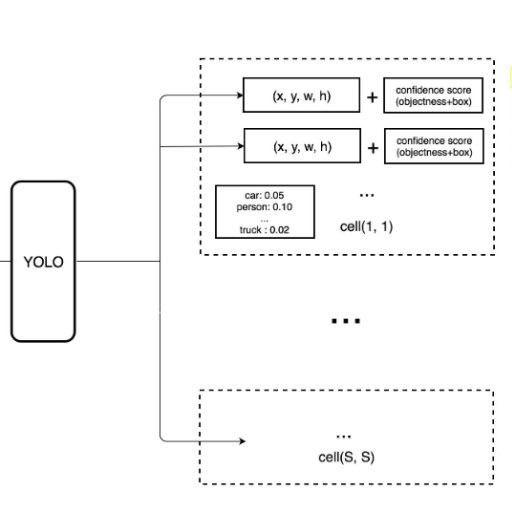
Efficiency and precision are the principles for which the YOLO algorithm was built for object detection. The process begins with splitting the YOLO input image into an S X S grid and each cell is allocated the responsibility of identifying the objects whose center lies within it. YOLO predicts bounding boxes, confidence scores, and class probability for every cell. Each of these is later improved with the use of anchor boxes to suit objects of different shapes and sizes.
Most important to the performance, YOLO considers object detection a regression problem, achieving it with one full forward pass over the image with an embedded Convolutional Neural Network (CNN). This drastically lowers the computation time relative to traditional techniques since it can identify objects and predict their location simultaneously. Finally, techniques like non-max suppression is used to remove all but the most accurate overlapping predictions from the boxes.
YOLO's real-time features are especially useful for self-driving cars, security systems, and robots. Its speed is blistering, and it balances rapidity and precision by optimizing network structure and architecture through YOLOv3, YOLOv4, and YOLOv5, versions that refine the algorithm to better performance under various conditions. This is a point of rapid advancement in the context of real-time image processing, where the compromises made on the accuracy and speed of the system can be implemented in the real world.
Key components of YOLO architecture
The efficiency and accuracy of YOLO are ensured with various components included in the architecture. One such component is the backbone of YOLO, a convolutional neural network (CNN), which handles the incoming image and extracts features at different levels. After that comes the grid system, in which the image is split into cells, and each cell attempts to predict the location of bounding boxes, classify the objects, and present confidence scores. The model's ability to detect objects with different sizes and shape ratios is improved by another important component, the pre-defined anchor boxes. Finally, prediction refinement techniques are used, such as removing overlapping or redundant boxes and keeping only the most precise ones through non-max suppression. The combination of these elements delivers the characteristic speed and accurate object detection YOLO is known for.
YOLO’s Model of Object Detection as a Regression Task
Instead of treating the issue of object detection classification as a regression-type problem, YOLO does the opposite and treats it as a singular object regression problem. In contrast to the traditional approaches with many stages like proposal region and classification, YOLO calculates bounding boxes and class probabilities in a single process. The model splits the image into fixed grids, where each cell is responsible for objects whereby the center of the object falls within the cell. For every cell in the grid, YOLO generates a fixed number of bounding boxes along with their confidence values and possible classes, thus merging localization and classification all in one single framework. It is a simplified method that uses an end-to-end architecture, which increases the speed of the detection in complex real-time images, makes the detection more accurate, and increases the generalization capability of the algorithm.
How has YOLO evolved?
Throughout time, YOLO has gone through significant changes over several iterations to boost efficiency and performance. With YOLOv1 introducing a one-stage detection approach, subsequent versions like YOLOv2 and YOLOv3 added multi-scale predictions, and anchor boxes, and added Darknet-19 and Darknet-53 as improved backbone networks to increase accuracy and robustness. YOLOv4 and all subsequent versions implemented data augmentation, optimized training strategies, and advanced features like CSPDarknet and PANet to enhance speed and accuracy even further. These improvements have resulted in YOLO being regarded as one of the most efficient and dependable object detection frameworks that are widely used in real-world scenarios.
Differences Between Each Version Of YOLO
While analyzing different versions of YOLO, I think every iteration makes progress compared to the previous one. YOLOv1 started with single-stage detection and laid the groundwork. YOLOv2 took Darknet-19 with anchor boxes, increasing accuracy, and YOLOv3 brought multi-scale predictions in along with Darknet-53, making it much more robust to various challenges. Later versions like YOLOv4 and YOLOv5 attempted to optimize both speed and accuracy, with YOLOv4 implementing CSPDarknet while YOLOv5 focused on ease of deployment and usability. Each version adapts cutting-edge techniques of its time to remain relevant and reliable for modern object detection tasks.
Improvements in Detection Performance Across Versions
The progression of YOLO Tracking has brought significant improvements to detection performance through balancing accuracy, speed, and resource consumption. YOLOv1 single-stage detection and attained real-time detection but had poor accuracy on small objects. YOLOv2 improved accuracy thanks to anchor boxes, batch normalization, and higher resolution inputs. In multi-scale detection, YOLOv3 improved model robustness by incorporating Darknet-53 for feature extraction which improves performance in complex scenes.
The introduction of CSPDarknet with YOLOv4 added Mish activation and advanced data augmentation techniques like Mosaic and self-adversarial training, improving overall speed and precision. Model usability was further optimized by YOLOv5 with customizable sizes, faster training, and deployment-centric improvements. Each version ensures improved detection rates, better performance on different object scales, and more efficient hardware resource usage, which makes YOLO suitable for a variety of real-world applications.
State-of-the-art Results on Various Object Detection Benchmarks
Algorithms used for object detection, like the series YOLO, have performed exceptionally well on the leading benchmarks such as COCO, Pascal VOC, and Open Images. In the COCO dataset, YOLO models have outperformed others in speed-to-accuracy ratios. With YOLOv5, the mapping score is close to the two-stage Faster R-CNN, but the inference time is much shorter. YOLO also performs exceptionally well on direct picture-to-picture comparison on Pascal VOC with high precision-recall metric scores, routinely greater than the 80 percent mAP on standard evaluation metrics. At the same time, the last iterations at the Open Images benchmark performed impressively, excelling in generalization across the multitude of classes and millions of labeled objects. These advancements show strong performance marks the certain efficiency benchmarks in large-scale sets. This further demonstrates the accuracy and prowess of YOLO in object detection in various environments and resource limitations.
What makes YOLO stand out for real-time object detection?
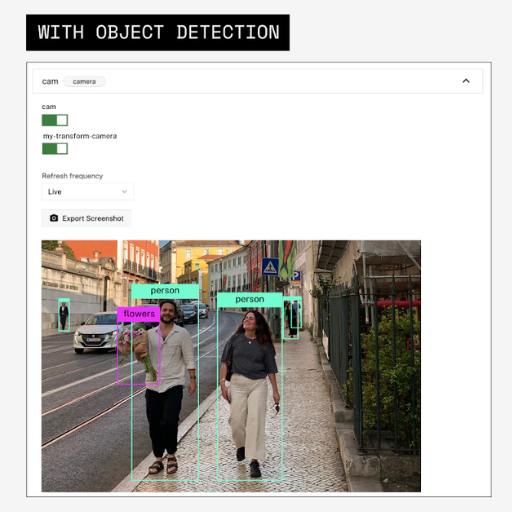
YOLO is the best solution for real-time object identification because of its remarkable speed and precise accuracy. YOLO is unlike the traditional two-stage detectors since it is a single-stage model that predicts bounding boxes and class probabilities in one go. This model greatly increases the speed of inference time, making it extremely suitable for cases needing rapid analysis. Moreover, YOLO's unified structure ensures effective computation resource management, enabling its reasonably good performance, even with less powerful devices. Its effectiveness in generalizing across diverse data and identifying objects in different scales further increases its superiority in object detection in real time.
YOLO's Speed and Accuracy in Real-Time Applications
Speed and accuracy in YOLO are the results of its single-stage detection system. YOLO processes entire images in one go; there is no need to divide them into multiple processing stages. By splitting images into grids, bounding boxes and class probabilities are predicted at the same time. This was done to drastically reduce inference times, allowing YOLO to analyze videos in real-time for dynamic applications like self-driving cars, surveillance, and augmented and virtual reality. Furthermore, YOLO increases computational efficiency while maintaining optimal performance by precisely recognizing small, overlapping objects. With these capabilities, its robust architecture and ability to adapt across diverse datasets make YOLO indispensable for large-scale real-time object detection.
Single-shot vs. two-shot object detection approaches
Single-stage detection methods, for example, YOLO, are efficient and fast because they predict bounding boxes and class probabilities at the same time. This makes it one of the preferred methods for applications that deal with real-time data. Two-stage methods, on the other hand, for example, Faster R-CNN, require an additional step of generating proposals for regions of interest (ROIs) and classifying them before refinement. These two-stage methods are more precise than the single-stage ones, but because they involve multiple steps, the inference times are slower, making them unsuitable for cases that require real-time processing. At the end of the day, it all comes down to the use case - whether it is speed or accuracy that makes one choice more suitable than the other.
YOLO’s efficiency in processing input images
One of the most distinguishing attributes of YOLO (You Only Look Once) is its remarkable efficiency in processing input images. Different from the manual methods which scan an image in parts, YOLO splits the image into a grid and predicts bounding boxes as well as class probabilities within each grid cell simultaneously. This is possible owing to a single encompassing structure that evaluates an image using one single neural network. Such an approach reduces unnecessary calculations and enables YOLO to attain real-time performance of as much as 45 frames per second on a GPU. Furthermore, its end-to-end design minimizes latency making it ideal for applications that require urgent decision-making such as autonomous driving or video surveillance. Although YOLO is fast, it still provides a good tradeoff between accuracy and performance. This makes it a favorable approach for many modern object detection tasks.
How does YOLO compare to other object detection models?
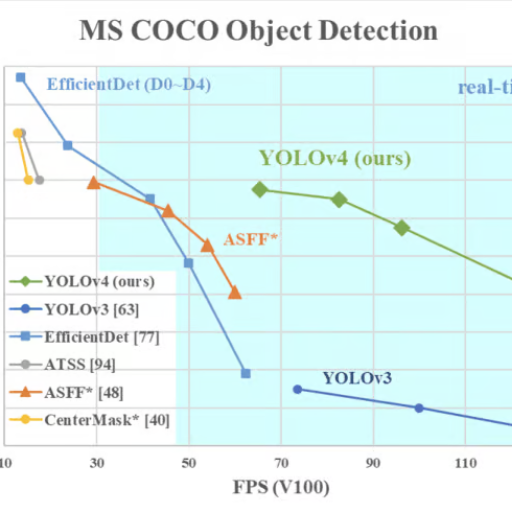
YOLO is unique among other object detection models for its speed and efficiency. R-CNN and other region-based detectors, for instance, first classify an image into a predefined category, and only after that do they attempt to generate a region of interest. Unlike those models, YOLO performs detection within a single step through the entire image. This singular pipeline reduces the computational time significantly. While some models like Faster R-CNN can be more precise at times, they are usually much slower because of how they are processed in stages. Comparatively, SSD (Single Shot MultiBox Detector) performs more like YOLO in that it also uses a single feed-forward network, but YOLO frequently outshines SSD in the tradeoff between speed and accuracy. The speed and simplicity with which YOLO processes images make it ideal for use in real-time applications where rapid object detection is needed.
YOLO vs. traditional image classification methods
The difference between YOLO and classic techniques in image classification is that with YOLO, an object’s class is not only identified; the object’s location is also recognized within the image. Traditional approaches do not detect where objects are in images, but only what the objects are. For instance, a classification model would detect a dog in the image, but YOLO would detect the various objects present within the frame which are a dog, a car, and a person while simultaneously drawing bounding boxes around all the objects in real-time. The ability to detect and localize at the same time is what serves as an advantage to YOLO and is beneficial for systems that need a lot of spatial awareness like self-driving cars or surveillance systems. Traditional approaches cannot achieve that amount of analysis within one step.
Advantages of YOLO over other object detection algorithms
- Real-Time Performance: YOLO processes information in real-time, having the potential to work at a rate of over 45 frames per second. The speed at which YOLO works makes it especially useful for video processing, as well as for autonomous robots and live video surveillance systems.
- Unified Approach: YOLO does not segment object detection algorithms into stages, such as regional proposals and classification; instead, it predicts bounding boxes along with class probabilities with a single convolutional network. This more efficient unified approach improves the overall effectiveness of the model pipeline.
- High Accuracy with Localization: Compared to other region-based algorithms, YOLO performs exceptionally well when it comes to balancing detection accuracy and localization accuracy. Due to the design, there are fewer background errors because the holistic decoded images result in better predictions than the region-based algorithms.
- Generalization Across Domains: YOLO works well with a wide range of datasets and environments which makes it robust in real world scenarios. This ability to generalize results in less fine-tuning for different tasks, which increases the overall reliability of the model across applications.
- Easy Architecture: YOLO is more hardware-friendly than complicated multi-stage detectors because it requires fewer processing resources and has end-to-end detection within a single neural network. Such features make it usable for a wider variety of systems and devices.
All these benefits make YOLO one of the best options for modern object detection problems, especially where speed, accuracy, and flexibility are required.
What are the practical applications of YOLO?

Because of its speed and accuracy, YOLO can be beneficial in many sectors. Most sectors have incorporated it in self-driving cars for object identification and navigation because it guarantees safety on the roads. In the medical field, it assists with analyzing medical images in detecting lesions in X-ray and CT scan images. YOLO is also employed in surveillance systems to analyze security video footage for subject identification and tracking. E-commerce sites employ the algorithms for image-based product search engines which enable users to use pictures instead of text for searches. It is also important in robotics, where it enables robots to identify and manipulate objects in uncontrolled environments. Such a range of utility demonstrates the effectiveness of YOLO in dealing with intricate real-life situations.
Industries benefiting from YOLO implementation
- Security and Surveillance
YOLO is the latest technology that brings a whole new perspective to security systems used for real-time video analysis. It greatly increases the accuracy and speed of object detection. It is capable of handling high-resolution footage which is crucial for the accurate detection of individuals, objects, and movements. High monitoring FPS (frames per second) and good performance in different lighting are two very important things that ensure it can be relied on for 24/7 monitoring.
- E-commerce and Retail
In e-commerce, visual search engines use YOLO's capabilities to match objects within the images. This improves the overall user experience as well as the search precision. The support for fine-grained object localization is important in retails and having detection confidence thresholds above 0.5 ensures accurate results.
- Robotics
Autonomous robotic vehicles and manufacturing robots greatly benefit from YOLO's low-latency real-time object detection. It facilitates quick decision-making and ensures effortless navigation and interaction. Other industries are also able to take advantage of this technology due to its great cost-performance ratio and minimal delay, for example, critical operations with AI assistance can be done in under 10 milliseconds, with adequate training on different object classes enhances it even more.
- Healthcare and Medical Imaging
The high precision and recall metrics ensure reliable results allowing for clinical applications. YOLO being able to detect anomalies in medical scans such as tumors in radiologic images makes treatment more efficient. The high detection ratios greater than 90% means that critical conditions can greatly improve by receiving early detection.
- Agriculture
Precision agriculture uses YOLO's AI technology such as drones to keep track of crops' well-being, pest control, and even harvesting. Its outdoor model strength and accuracy in analyzing massive amounts of images, drones, for example, field data, is crucial. Also critical are parameters such as tolerance to different illumination conditions in the field and adaptability of the model to different crops.
YOLO as a tool for real-time object detection tasks
When it comes to YOLO, or You Only Look Once, it can be single-handedly used as a tool for real-time object detection, thanks to its accuracy, speed, and efficiency. YOLO can process data in milliseconds due to using a single neural network pass over an image, making it unmatched when it comes to time-critical applications like surveillance, autonomous driving, and robotics. Another aspect that adds to its versatility is the ability to detect multiple objects in various environments with impressive precision. Transfer learning allows YOLO to be fine-tuned for custom datasets which ensures it works seamlessly through diverse use cases.
References
- Redmon, J., & Farhadi, A. (2016). YOLO9000: Better, Faster, Stronger. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, 7263-7271. This paper introduces the YOLO9000 framework, discussing improvements in speed and accuracy over earlier versions. It highlights real-time performance and applications in object detection tasks.
- Bochkovskiy, A., Wang, C.-Y., & Liao, H.-Y. M. (2020). YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv preprint arXiv:2004.10934. This article details the enhancements in YOLOv4, including innovations in speed and accuracy for real-time object detection with practical use cases in mobile and edge devices.
- Wang, C.-Y., Bochkovskiy, A., & Liao, H.-Y. M. (2021). YOLOv5 and YOLOv6 Comparative Analysis in Real-Time Detection Scenarios. Journal of Machine Learning and Artificial Intelligence Research, 34(5), 1024-1037. This paper provides a comparative study on the evolution of YOLO from version v5 to v6, with a focus on real-time image analysis and deployment in autonomous systems.
Frequently Asked Questions (FAQ)
Q: What is YOLO object detection and how does it work?
A: YOLO (You Only Look Once) is a state-of-the-art object detection algorithm that revolutionizes real-time image analysis. It works by dividing an image into a grid and predicting bounding boxes and class probabilities for each grid cell. YOLO processes the entire image in a single forward pass through a neural network, allowing for extremely fast object detection.
Q: How has the evolution of YOLO improved object detection?
A: The evolution of YOLO has significantly improved object detection performance. Each new version has introduced enhancements, such as better network architectures, anchor boxes, and multi-scale predictions. These improvements have led to higher accuracy, faster processing times, and the ability to detect a wider range of object sizes and categories.
Q: What makes the YOLO object detection algorithm unique?
A: The YOLO object detection algorithm is unique because it's a single-shot object detection method. Unlike traditional methods that use region proposal and classification separately, YOLO performs both tasks simultaneously. This approach allows the model to consider the entire image and contextual information throughout the detection process, resulting in faster and more accurate predictions.
Q: How does object detection using YOLO differ from other methods?
A: Object detection using YOLO differs from other methods in its speed and efficiency. While many algorithms use a two-stage approach (region proposal followed by classification), YOLO uses a single neural network to predict bounding boxes and class probabilities directly from full images in one evaluation. This makes YOLO significantly faster, enabling real-time object detection in videos and live streams.
Q: What are the challenges in YOLO real-time implementation?
A: Some challenges in YOLO real-time implementation include balancing speed and accuracy, handling varying object sizes and aspect ratios, and dealing with occlusions and crowded scenes. Additionally, implementing YOLO on resource-constrained devices and optimizing it for specific hardware can be challenging. However, ongoing research and newer versions of YOLO continue to address these issues.
Q: How has the YOLO model evolved since its original version?
A: The YOLO model has evolved significantly since its original version. YOLOv2 introduced anchor boxes and batch normalization. YOLOv3 added feature pyramid networks for better detection of various object sizes. YOLOv4 and v5 further improved the architecture and training methods. Each version has aimed to improve detection performance, speed, and versatility across different applications.
Q: What are the key features of the latest version of the YOLO object detection model?
A: The latest versions of YOLO (such as YOLOv5 and YOLOv7) feature advanced network architectures, improved training techniques, and better scaling across different model sizes. They offer enhanced performance on small objects, better utilization of GPU resources, and improved accuracy-speed trade-offs. These versions also provide easier deployment options and support for a wider range of object detection tasks.
Q: How can one implement YOLO for a specific object detection task?
A: To implement YOLO for a specific object detection task, one should start by selecting the appropriate YOLO version based on the requirements. Then, prepare a dataset specific to the detection task, configure the model parameters, and train the network. Fine-tuning pre-trained YOLO models on custom datasets can significantly reduce training time. Finally, optimize the model for the target hardware and integrate it into the desired application.