Unlocking the Power of Large Language Models: A Comprehensive Guide to LLMs and Generative AI

The astonishing pace at which artificial intelligence is evolving has brought considerable changes to how machines understand and synthesize human speech. Large Language Models (LLMs) developed by OpenAI, including the GPT series, are prime examples. These models can create human-like authored content, as well as analyze and provide solutions to multifaceted issues. But what are the underlying processes behind the model's functions? What are the defining characteristics that make them so effective? And how can their employment be optimized in varied disciplines?
This guide aims to provide a deep and precise analysis of LLMs and their function in generative AI. We will kick off with an overview of the building blocks of LLMs, identifying the amalgamation of machine learning algorithms with LLMs’ immense databases. From there, we will turn to LLMs' implications, analyzing how they facilitate creativity, improve business models, and drive scientific advancements. Readers will also learn about the socioethical challenges posed by technology, especially those associated with prejudice, deception, and protection of personal information.
This tutorial will give you deep insights into the possibilities of LLMs along their inner workings, and their future relevance to the world of artificial intelligence. Whatever your AI experience may be – a hobbyist, IT expert or simply interested in this innovative domain – this guide will enable you to appreciate everything LLMs and generative AI offer.
What are Large Language Models (LLMs) and how do they work?
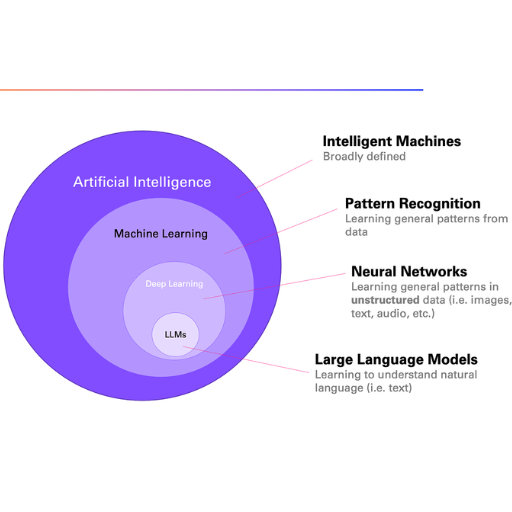
An LLM, or Large Language Model, is a type of artificial intelligence that can effortlessly speak and write in languages, which is made possible by advancing automation technology capable of developing human-like voice and paradigms. Their training started with reading massive datasets including but not limited to books, articles, and digital texts so that they would be able to recognize the framework, syntax, and context of everyday language. By applying and predicting the sequence of words, the model can produce contextually relevant answers using an advanced deep learning technique called a neural network system. In simple terms, the model is trained by exposing it to extensive language patterns, which is later refined for specific goals; this process is termed ‘pre-training’ and ‘fine-tuning’ respectively. Given the sheer magnitude of their training data combined with workhorse level computational resources, such models can perform tasks such as language translation or summarization along with countless others like setting an entirely new benchmark for a wide assortment of industries.
Understanding the Basics of Neural Networks and Deep Learning
Deep learning, which is a subset of artificial intelligence (AI), relies on neural networks as its main tool, just like a human being uses their brain for processing information. Neural networks consist of "neurons" that work together to analyze and interpret data, and these neurons are arranged in layers which are interconnected with one another. These layers are classified into three categories: the first one is the input layer which receives the data, the second one is the hidden layers which process the data, and finally, the output layer which provides the processed data.
Deep learning distinguishes itself from other types of machine learning through the use of neural networks that have multiple hidden layers. With that, vast and complex datasets can be processed accordingly. Each neuron may receive a connection assigned to it which bears “weight” and “bias.” Once training suffers prediction error, these parameters will have to go through alteration. Techniques such as backpropagation or gradient descent enable the training process to improve, thus reducing errors.
In comparison to the conventional methods of image recognition and natural language processing, deep learning makes use of extensive datasets. Algorithms paired with enhanced computational strength as well as deep learning data applications have revolutionized autonomous car design as well as oncology diagnostic scope. It’s safe to say that deep learning is without a doubt continually transforming technology today.
The role of transformers in LLMs
For the Large Language Models (LLMs), texts like documents and sentences are generated and processed with high precision and coherence. These models utilize the architecture of a transformer which applies self-attention and positional encoding to comprehend the placement of words in a stretch with greater context. Through these methods being employed, LLMs are capable of producing contextually pertinent and sophisticated outputs. This makes them potent for all kinds of works such as conversing, summarizing, and translating. Almost all modern AI models, GPT and BERT for instance, are built on the transformer framework and this is a testimony to the paradigm shift it has caused in the field of AI.
How LLMs are trained on vast amounts of data
Training large language models (LLMs) involves the use of vast datasets so that they can understand and produce human-like text. Initially, this stage starts with data collection from a variety of sources such as books, scientific articles, websites, and public records to ensure a variety of topics, domains, and even languages are captured. During the training phase, unsupervised learning is utilized where the model attempts to predict missing words in a data sequence, which improves context and semantics. Gradient descent and other advanced methods optimize the set of the model's parameters by reducing the overall errors after several training cycles or epochs. Training LLMs requires tremendous computational power and resources, usually utilizing distributed computing systems that have GPUS or TPUS to deal with the massive amounts of data as well as complexity. Also, using supervised learning, models go through coarse-grain tuning on specific tasks or domains to increase accuracy for various real life scenarios.
What are the key applications and use cases for Large Language Models?
Broadly speaking, the use of Large Language Models (LLMs) is varied and widespread. They have some of the prominent use cases such as natural language processing (NLP) tasks like language translation, text summarization, and sentiment analysis, which eases communication between different languages and mediums. LLMs are also greatly integrated with virtual assistants and chatbots providing personalized and automated customer care and user interaction. They are also transforming content development by helping in creating articles, reports, and even novels with little or no human supervision. Other relevant uses include assisting software developers with code generation, analyzing large datasets or writing reports for medical research, and adaptive learning in educational technology. The understanding and generation of human-like text have made them key for automating intricate and diverse activities.
Natural language processing and understanding
The fields of artificial intelligence that focus on enabling machines to understand and manipulate human language are called natural language processing (NLP) and language understanding. Chatbots, sentiment analysis and real-time translations are just some of the advancements that have come from the technology. NLP uses deep learning models and algorithms to automate the interpretation of human language which, in turn, transforms industries such as healthcare, education, and customer service. NLP technology is changing so rapidly that the solutions being provided are constantly evolving to be more contextually accurate and astute.
Language Translation and Generation
The processes of language translation and generation hinge heavily on the functioning of sophisticated algorithms in Natural Language Processing (NLP) that facilitate the translation or generation of text from or to any specific language. Technologies that assist in providing these functionalities include machine translation tools like Google, which applies Deep Learning Neural Network models to translate over sixty languages into and from English using a framework called Neural Machine Translation (NMT). Further, NMT implements a transformer architecture with an attention feature that concentrates on different parts of the input language for translation, which ensures an increase in the quality and accuracy of the output language.
Some of the technical details that are considered important for the functioning of the systems identified above are the number of the encoder and decoder layers which typically vary between 6 and twelve, the number of attention heads, which is more common with 8 or 12 heads, and the size of the embedding which is usually set at 512 or 1024. The capacity of the system to capture the intricacies of the language improves with the setting of these parameters.
On the other hand, language generation is done by apps like OpenAI's GPT series or Google's T5, which both rely on transformer networks. Such systems undergo a pretraining process using enormous amounts of data followed by fine-tuning sessions for specific functions such as text summarization or chatbot conversation. A crucial factor here is the magnitude of the model, given in billions of parameters, for example, GPT-3 with its one hundred seventy-five parameters is capable of generating human-like text with an astonishing understanding of context.
With support from extensive datasets and computational resources, these technologies applied in translation and content generation sustain continuous enhancement of speed, accuracy, and flexibility.
AI chatbots and conversational AI
With AI chatbots and conversational AI, technology is advancing significantly. These systems can comprehend and produce human-like text using sophisticated machine learning models, managing difficult questions alongside contextually rich dialogues. Because of these vast datasets, they seem to evolve, and become more efficient by the minute. They are already changing customer service, healthcare, and education by automating and personalizing assistance, which shows there is still so much more left to explore.
What are the advantages and limitations of using Large Language Models?

Advantages of Using Large Language Models
Few tools reveal and boast the myriad of purposes that Large Language Models (LLMs) cover. From advanced text comprehension capabilities to formulating text that is indistinguishable from human produced language, these tools are multi-faceted at best. Additionally, LLMs can identify the most pertinent data from immense datasets and automate sophisticated tasks like generating content, guiding customers, or translating languages. On top of everything, the models boast the flexibility to cater to improving user interaction, scientific evolution, and cutting edge research.
Limitations of Using Large Language Models
Regardless of their exceptional performance, LLMs are bound to have limitations. By design, autonomous LLMs can produce content that is incorrect or even prejudicial based on the data they were given. Additionally, basic but often overlooked, certain subjects require context or a more specific answer, which these models fail to provide. Moreover, the sheer amount of computation needed to train these models and run them comes at a cost, particularly one surrounding their use of energy and the common public’s ability to access them. The ethical side of things is also problematic, with rampant possibilities of misuse, a couple of other risks need attention, too, and account for privacy as well.
Benefits of LLMs in various industries
- Healthcare
LLMs are dramatically changing patient care through advancements of medical research and diagnostics. These devices can study comprehensive databases, assisting in finding treatment patterns and making disease forecasts. Their ability to analyze and understand the patient data enables better healthcare plans to be formulated for the benefit of the people.
- Education
These models are making personalized tutoring a reality by providing custom educational resources and on-demand instructional assistance. They can assist teachers, promoting the creation of adaptive learning technologies, virtual teachers, and effective evaluation systems for feedback.
- Customer Service
Through advanced chatbots and virtual assistants capable of addressing complicated customer queries, LLMs have greatly improved customer support operations. Companies now enjoy improved response times, constant availability, and better customer relationships, which leads to a decrease in the human effort needed for repetitive tasks.
- Finance
LLMs facilitate risk management, fraud detection, and investment strategies through predictive analysis, as well as aiding in the processing of enormous sums of financial data. Natural language understanding also assists their customer's communication and compliance supervision functions.
- Entertainment and Content Creation
LLMs help accelerate the creation of content such as articles, scripts, or even dialogue within creative projects. They're leveraged for engaging audiences through personalization as well as localization and subtitling.
In general, LLMs serve as a facilitator between people and machines, providing smarter ways to automate tasks, encourage new ideas, and respond to digitalization. However, adopting LLMs still requires great ethical oversight as well as energy-sensitive measures to guarantee fairness and mitigate harm.
Potential risks and ethical concerns
There is always some potential risk involved with LLMs, and I recognize some key issues that can cause ethical concerns. First, the risk of bias conforms to the data societal prejudice, meaning that LLMs are trained on vast datasets which could tend to reflect biases. This can output harmless outputs that may be dangerously impactful. Second, there is always a concern of privacy as sensitive information is at risk of being manipulated irresponsibly. Third, the enormous energy consumed to train LLMs heavily contributes to a negative environmental impact, which increases the need for sustainable provisions. The worst part about these challenges is that they need to be resolved without making LLMs nonethical or unresponsible.
Overcoming biases in training data
A single approach is inadequate to counter biases in training data, instead, it requires a more integrated one. First, datasets must be more representative of different demographics, cultures, and viewpoints, which means that they must be more inclusive. Such inclusive and representative data helps to eliminate preconceived generalizations. Second, finding and removing biased patterns is an active process, and as such utilizes sophisticated methods like algorithmic audits that help find and eliminate disproportionate effects within datasets. Third, fairness is also a construct that should be embedded into the logic of the model. When developing a model, there should be a clear and robust system of accountability. Moreover, diverse teams can help fill gaps in perspective and potential blind spots during the data collection and training processes. Post-deployment, the model requires ongoing monitoring and improvement to remove biases that occur over time. These methods facilitate building systems of artificial intelligence that respond ethically and equitably.
How are Large Language Models different from traditional AI systems?
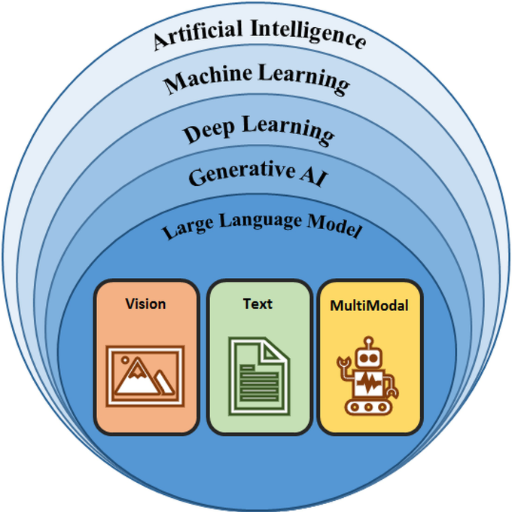
LLMs have a distinct difference with ‘conventional’ AI systems and these differences stem from their scope, flexibility, and learning methods. While traditional AI systems are usually built to accomplish specific processes, LLMs boast the capability of being trained on a plethora of varied data, which subsequently allows them to carry out various language-oriented activities. In addition, the model’s architecture, which is frequently predicated on transformer models, enables them to excel in the processes of understanding and ‘producing’ natural language. Additionally, LLMs outperform traditional AI models that typically need specialized programming and datasets for every task due to their ability to adapt without needing specific retraining for different tasks or domains.
Comparing LLMs to Other Machine Learning Models
As pointed out in a previous section, a key strength of LLMs over traditional machine learning models stems from a model’s ability to scale and broaden. While common models are limited to single tasks and require extensive retraining with specific datasets, LLMs are trained to perform a multitude of tasks with little to no extra additional effort. This broad adaptability is due to the model’s ability to process and produce natural language using intricate transformer-based architectures along with proficient skills in translation, summarization, and question answering in multiple domains.
Another point of divergence comes from the method of processing data. Unlike other models which need a clean set of labeled data with specific inputs, LLMs work with unstructured and diverse datasets with relative ease. With this, LLMs have improved ability to recognize context or patterns within data to provide more comprehensive and flexible outputs. Furthermore, Less reliance on labeled data means reduced dependency on expensive and time-consuming self-supervised learning techniques, allowing greater flexibility to LLMs.
Still, self-supervised learning comes with particular strengths, but when delving into simpler, narrowly defined tasks, common models can often explain outcomes with greater efficiency. When using LLMs for narrow applications, the model’s need for extensive computational resources can also make it less cost-effective. In general, these models possess unique advantages which are all dependent on the problem being solved.
The concept of foundation models
As language models like GPT and BERT have shown, foundation models refer to larger-than-life machine learning models that have been trained on massive datasets and can be easily modified for different activities. A foundation model provides the underlying base of specialized knowledge with the capability to further optimize it for distinct functionalities such as translation, summarization, or even image recognition. I can tackle numerous issues with astonishing versatility due to extensive pre-training with foundation models, however, their computational requirements can pose a challenge, depending on the task.
Multimodal Capabilities of Advanced LLMs
Developers of sophisticated large language models (LLMs) are building systems capable of understanding modulated inputs, including text, image, audio, and video data. LLMs using both language and vision comprehension can undertake advanced activities such as captioning images, sentiment analysis, and transforming video files into data extracts. Well-known examples are OpenAI’s GPT-4 and Google’s PaLM-E models, which specialize in the fusion of modalities. These models aid in content development, creation of assistive devices, and fundamental scientific investigations. The range of their application is further widened by the precision and depth of interaction, which pushes every sector into further development.
What is the future of Large Language Models and Generative AI?

As limitless as the world can be, the world of Large Language Models (LLMs) and Generative AI combines and blends the two worlds, harnessing new developments in several domains. Enhanced efficiency means these technologies will deliver superior quality while consuming less computations. The level of personalization and contextual understanding will make relationships more effortless and approachable, transforming customer service, healthcare, education, and creative fields. Besides, with the growth of ethical scaffolds and laws, the systems will have less space for harmful innovation and will be safer for responsible usage. Setting up a balance between AI and human intelligence, brand new ways of working will emerge, providing powerful capabilities to address intricate global issues.
Emerging trends in LLM development
Trends on the development of large language models (LLMs) underline efficiency, accessibility, and ethical issues. Firstly, highly capable models which are smaller in size and easier to compute are becoming the most desired. Achieving and deploying models with high performance and fewer resources is aided by methods such as model distillation and parameter-efficient techniques. Secondly, customization of models to suit certain industries or tasks is becoming common. The healthcare sector, finance, and customer relations are some of the fields which are aided by this trend. The attached report illustrates the social usability effect customization of models serves. Final focus goes toward ethical AI, which in practice seeks to remove biases, ensure responsibility, and increase accountability. The societal effect, both positive and negative, is being dealt with by academic institutions, private firms, and governments, which are together taking these measures. Following signals emphasize the growing effectiveness of LLMs will have with a wide range of applications while being ethical and easily multifunctional.
Potential breakthroughs in natural language understanding
I perceive the context comprehension advancements as the natural language understanding prospective breakthroughs’ frontiers. In themselves, further progression in multimodal learning, which integrates text, image, and speech data, will greatly expand their capabilities. Besides, optimizing models for under-resourced languages and dialects will further inclusion and global outreach. Along with these improvements comes real-time interaction and more elaborate ethical precautions that will profoundly change the way LLMs see and interact with the world.
Integration of LLMs with Other AI Technologies
Many people believe that the integration of large language models (LLMs) with other technologies such as computer vision, robotics, or the Internet of Things (IoT) is changing the scope of artificial intelligence. The implementation of LLMs together with computer vision systems makes it possible for AI to understand complex multimodal data like text, images, and videos, leading to automated video analysis and better creative aids. Their combination with robotics enhances human-robot interaction through natural language understanding, which allows easier execution of tasks to be performed in dynamic environments. IoT shaped systems benefit tremendously as well, as LLMs are capable of receiving and interpreting data from other devices and responding adequately, which leads to smarter systems in home automation and industrial monitoring. The incorporation of different AI technologies together with LLMs enhances the automation and interactivity of devices, therefore pushing the innovative frontiers to more advanced context aware solutions for various industries.
References
Frequently Asked Questions (FAQ)
Q: How do large language models work?
A: Large language models (LLMs) work by using deep learning techniques, particularly the transformer model architecture, to process and generate human language. They are trained on vast amounts of text data, allowing them to predict the next word in a sequence and generate coherent text. LLMs use self-attention mechanisms to understand context and relationships between words, enabling them to comprehend and generate human language with remarkable accuracy.
Q: What are some common applications of LLMs?
A: LLMs are used in various applications, including: 1. AI chatbots like ChatGPT 2. Language translation 3. Content generation 4. Text summarization 5. Sentiment analysis 6. Question-answering systems 7. Code generation and completion. These AI models can be applied in industries such as customer service, content creation, and software development.
Q: How are LLMs trained?
A: LLMs are trained on huge datasets of text from various sources, including books, websites, and articles. The training process involves exposing the model to this data and adjusting its parameters to minimize prediction errors. Many LLMs are trained using unsupervised learning techniques, where the model learns patterns and relationships in the data without explicit labeling. Fine-tuning on specific tasks or domains can further enhance their performance for particular applications.
Q: What are the limitations of LLMs?
A: Some limitations of LLMs include: 1. Potential for generating biased or inaccurate information 2. Lack of true understanding or reasoning abilities 3. Difficulty with tasks requiring real-world knowledge or common sense 4. High computational requirements for training and running large models 5. Challenges in maintaining up-to-date information 6. Ethical concerns regarding data privacy and potential misuse. It's important to be aware of these limitations when using LLMs in various applications.
Q: How does ChatGPT differ from other LLMs?
A: ChatGPT is a specific implementation of an LLM developed by OpenAI. It is fine-tuned for conversational tasks and uses reinforcement learning from human feedback to improve its responses. While it shares many characteristics with other LLMs, ChatGPT's training process and optimization for dialogue make it particularly effective for chatbot applications and interactive conversations. However, the core principles of how it works are similar to other transformer-based language models.
Q: What is a prompt in the context of LLMs?
A: A prompt is the input text given to an LLM to generate a response or complete a task. It can be a question, a partial sentence, or a set of instructions. The quality and structure of the prompt significantly influence the output of the model. Effective prompt engineering involves crafting inputs that guide the model to produce desired results, whether for creative writing, problem-solving, or information retrieval tasks.
Q: Can LLMs understand and generate content in multiple languages?
A: Yes, many LLMs are trained on multilingual datasets and can understand and generate content in multiple languages. Some models are specifically designed as multilingual models, capable of translating from one language to another. However, the performance may vary depending on the amount and quality of training data available for each language. Some advanced LLMs can even perform zero-shot translation, translating between language pairs they weren't explicitly trained on.
Q: What are the advantages of using LLMs in AI applications?
A: The advantages of LLMs in AI applications include: 1. Ability to understand and generate human-like text 2. Versatility across various language-related tasks 3. Reduction in the need for task-specific training data 4. Capability to perform well on new tasks with minimal fine-tuning 5. Potential for creative and diverse outputs 6. Continuous improvement through ongoing training and updates. These advantages make LLMs powerful tools for a wide range of artificial intelligence applications.