Revolutionizing Machine Learning: The Ultimate Guide to MLOps Pipeline Automation
The pace at which machine learning is transforming entire industries is nothing short of remarkable. It is driving innovation and smarter decision-making. Accomplishing efficient and reliable implementation of machine learning goes beyond just having strong algorithms; it requires meticulously organized operational processes. This is where MLOps (Machine Learning Operations) comes into play as a liaison between empirical models and fully functional ones.
Through this blog post, we will break down the MLOps automated pipeline and explain how automation is changing the traditional way of doing work. We will cover all the vital stages from building and deploying a model to monitoring and retraining it. Understand the foundational elements of an MLOps pipeline, the operationalization of machine learning, and the role automation plays in scalability, collaboration, and trustability.
MLOps aims to revolutionize the way machine learning operations are conducted. By the end of this article, we hope that data scientists, engineers, and even business leaders will be knowledgeable enough to leverage MLOps and remain competitively agile in this rapidly changing data-centered world.
What is MLOps and why do we need it?
MLOps, or Machine Learning Operations, is a collection of processes that improves the automation and maintenance of machine learning models in production. It blends DevOps practices with machine learning to facilitate cooperation between data science and operations teams.
As the challenge of managing machine learning projects increases, the need for MLOps increases. Without it, scaling models, reproducibility, and maintaining consistency across various environments becomes extremely difficult. MLOps resolves these challenges by automating workflows, enhancing model reliability, and supporting CI/CD processes to help organizations fully realize the value of their machine learning efforts.
Defining MLOps: Machine Learning Operations explained
Machine learning operations, or MLOps, is the process of facilitating andautomating the development and deployment of machine learning models within a production environment. It integrates the processes of data science and operation by making sure that the models are put to practical use. MLOps applies DevOps practices to the machine learning cycle, allowing an organization to achieve process automation, model management, and cross-environment reliability.
The crucial need for MLOps in modern data science
MLOps Model Operations attempts to solve the most challenging issues in contemporary data science like scaling machine learning systems, reproducibility, and model performance over time. The rapid adoption of AI automation increases the need of organizations to incorporate advanced machine learning features into pre-existing systems with little to no friction. On the other, MLOps aids in mitigating these problems by automating workflows, orchestrating data pipelines, and applying continuous integration and delivery of well-performing models. In addition, it reduces the chances of failure in critical systems by monitoring for drift, errors, security threats, and overall model performance, thus enhancing operational security. MLOps has ensured that with control over the data science, IT tools, and business activities, the four pillars of innovation, speed, flexibility, and efficiency can be achieved simultaneously and in any scale.
Key benefits of implementing MLOps practices
- Greater Efficiency: The implementation of MLOps allows me to automate much of the manual work associated with the development and deployment of machine learning models. I save a lot of time.
- Increased Model Accuracy: Because I have automated some monitoring functions to detect data drift and performance issues, I ensure that my models are correct and consistent throughout their application.
- Improved Scalability: Having MLOps deployed means that I am now able to expand machine learning operations to any scale and cope with larger volumes of work without degrading quality and speed.
- Shorter Time to Market: I reap the benefits of MLOps by shortening the time it takes for models to progress from experimentation to production. As a result, I provide insights and solutions much faster.
- Reduced Risk: I raise my solutions’ credibility by eliminating the system failure chances resulting from lack of error, security, or compliance attention in advance, building trust in my solutions.
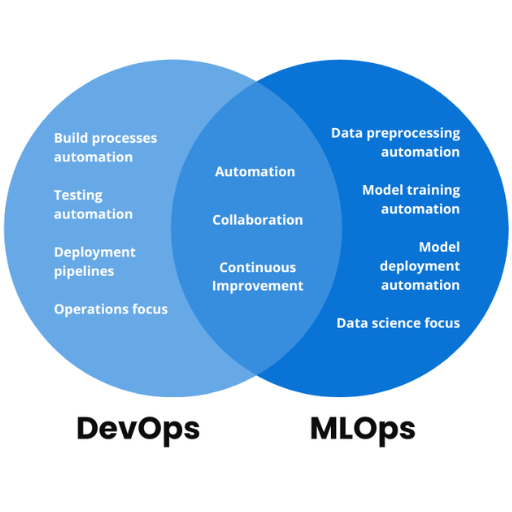
How does MLOps differ from DevOps?
Even though MLOps and DevOps have in common automation, team collaboration, and continuous integration, their focus and implementation are different. The MLOps Vs DevOps comparison must consider that DevOps concentrates on the processes associated with software application development and deployment, which includes application code, infrastructure, and system dependencies. Rather, MLOps tackles the challenges unique to machine learning, including the control of data pipelines, model training, versioning, and the monitoring of models in production. Because of the additional workflow complexity required to accommodate the unique needs of ML models and their dependence on data, MLOps is more complicated than conventional DevOps.
Comparing MLOps and DevOps: Similarities and differences
In my opinion, both MLOps and DevOps appear to have harnessed the notions of automation, continuous integration/continuous delivery (CI/CD), and interdepartmental cooperation on model or application deployments. Both seek to amplify operational productivity and service quality in production environments. Nevertheless, MLOps stands out much more because of the intricacies involved with workflows of machine learning. MLOps, in contrast to DevOps, has to deal with the cyclical processes of training and retraining models, large-scale data set management, algorithmic experimentation, and real world model validation. The focus on data makes MLOps much more fluid and flexible than the more stringent processes employed by DevOps.
Unique challenges addressed by MLOps
In my opinion, MLOps addresses some particular problems that originate from machine learning systems. One of the most crucial aspects is the management of versioning of datasets and models, which often changes during the production and experimental phases. Furthermore, ensuring reproducibility of results requires robust tracking of experiments that link models to datasets and their associated configurations, which these processes also do. Supporting scalability and model drift control, to me, is a final major challenge, as there is a need for cross-environment performance maintenance within constantly adapting, dynamic data. These features, in my opinion, create the rationale for MLOps regions which aim to streamline and stabilize the entire life cycle of machine learning projects from initiation to completion.
Integrating MLOps with existing DevOps practices
Combining MLOps with existing DevOps processes is about merging software development pipelines with machine learning workflows. While DevOps deals with automating, tracking, and optimizing the life cycle of software development, MLOps applies these concepts to unique issues in machine learning, such as data versioning, model training, and deployment.
To incorporate MLOps, teams should add steps for validating data, training models, and evaluation in addition to traditional code testing in CI/CD pipelines. Standardizing containers for orchestration, as well as model deployment with tools such as Kubernetes, support automation of machine learning workflows within a DevOps framework. Furthermore, data scientists, ML engineers, and DevOps teams must work together to reach a shared understanding of objectives and processes to facilitate cooperation.
Alongside these, organizations also gain through the adoption of MLOps and DevOps platforms that ease workflow and scalability. Lastly, unobtrusive but effective tracking of the deployed models is required to identify performance changes while avoiding model drift, thereby always keeping the ML systems dependable and strong.
What are the core principles of MLOps?
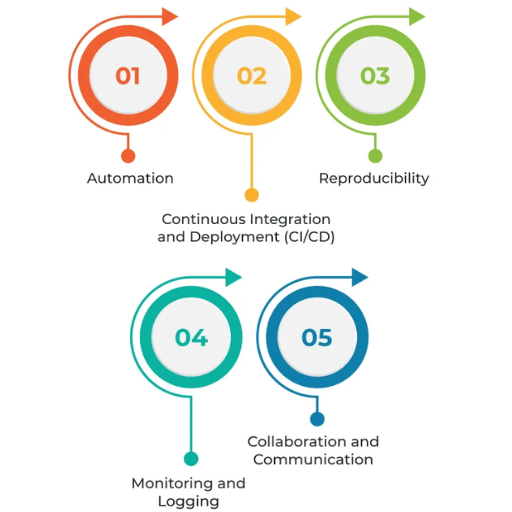
- Collaboration and Communication: Smooth communication among data scientists, engineers, and DevOps teams to ensure their activities are synchronized toward common objectives.
- Automation: Reduction of repetition for basic model-related undertakings such as training, testing, deployment, and monitoring for maximized efficiency and reduced mistakes.
- Continuous Integration and Deployment (CI/CD): Regular updates on code and model integration with constant maintenance and automated deployment for effortless scalability.
- Model Monitoring and Management: Sustained surveillance of model performance to proactively address issues such as drift while making the required changes to restore reliability.
- Reproducibility: Achieving the same output consistently within multi-environment configurations using meticulous experiment, data, code, and configuration management.
- Scalability: Establishing a system capable of increasing in complexity and volume of data or machine learning models it can sustain.
These principles work in unison to achieve more efficient, robust, and scalable machine learning operations.
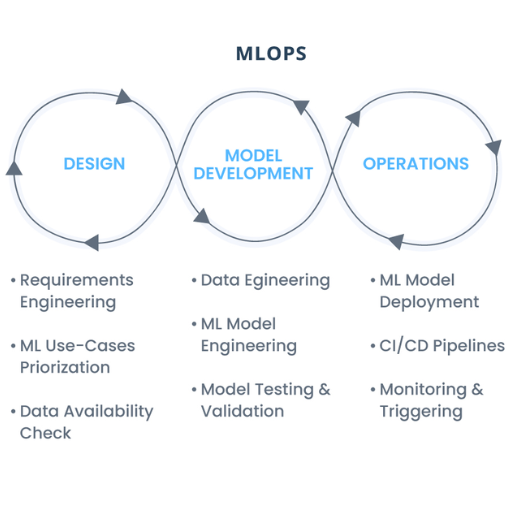
Understanding MLOps maturity levels
MLOps maturity levels represent different stages of an organization’s ability to manage and operate machine learning models. At the lowest level of maturity, teams respond to challenges by applying ad-hoc processes that are manually coordinated and poorly automated, which, as with much of MLOps, can lead to inefficiencies. With higher maturity levels, organizations can practice more reliable and scalable versioning, CI/CD pipelines, and automated workflows. In the most mature level, MLOps are fully automated with no human intervention required during deployment and maintenance of machine learning systems. There is real-time monitoring, reproducibility, and dynamic scaling of the systems along with seamless integration of machine learning utilities. This evolution enables organizations to achieve better iteration cycles coupled with greater business value extraction from their ML models.
The essential components of an MLOps framework
In my opinion, a robust MLOps framework relies on few components. First, there should be versioning of the code and data and traceability of every iteration with appropriate locking and branching strategies. Second, the monitoring and observability tools enable flagging performance anomalies or drift in real time which is crucial for model performance. Finally, reliable and efficient automated scalability, alongside optimized cost infrastructure resource management, provides the solution. Together, these aspects build the foundation to support effective and optimum machine learning operations.
Best practices for implementing MLOps in your organization
- Adopt Version Control for Code and Data
Incorporate version control systems such as Git for code changes along with tracking tools like DVC or LakeFS for datasets. This makes sure that reproducibility and traceability is done across multiple models and experiments.
- Implement Continuous Integration and Delivery (CI/CD) Pipelines
Create automated CI/CD pipelines with testing, training, and validation of models to be performed before deployment. Jenkins, GitHub Actions, or GitLab CI help streamline these workflows while unit and integration tests are integrated.
- Ensure Data Quality and Consistency
Validate all incoming data for accuracy and consistency using tools like Great Expectations at regular intervals. Create automated pipelines for data preprocessing and feature engineering to help reduce errors and ensure data integrity.
- Monitor Models in Production
Implement monitoring systems to check model metrics like accuracy, latency, and response times. Moreover, utilize Prometheus, Grafana, or ML monitoring tools like Evidently to track data drift, concept drift, and anomalies in real-time.
- Automate Scalability with Infrastructure Management
Utilize resource management for container orchestration tools like Kubernetes or cloud services like AWS SageMaker or Google Cloud AI. Implement auto-scaling policies to improve system response time for peak workloads.
- Foster Cross-Functional Collaboration
Encourage collaborative efforts from data scientists, engineers, and operational staff. Common tools, effective communication, and embedded systems like MLflow or Kubeflow can streamline processes and foster cooperation.
- Establish Governance and Compliance Frameworks
Set and manage guidelines to make sure compliance with policies and other regulatory standards is met. This involves protecting privacy (like GDPR) and security through encryption and access management in IAM tools (AWS or Azure AD).
- Continuously Retrain and Update Models
Plan model retraining for periods when tracked metrics such as performance drop-off or data drift thresholds are hit. Automate changes in your pipeline to update and redeploy enhanced models so that there is no need for manual intervention.
By implementing these actions, organizations can develop effective and efficient MLOps systems that are robust and scalable and ensure successful machine learning deployment with minimal operational downtime.
How can MLOps improve the machine learning lifecycle?
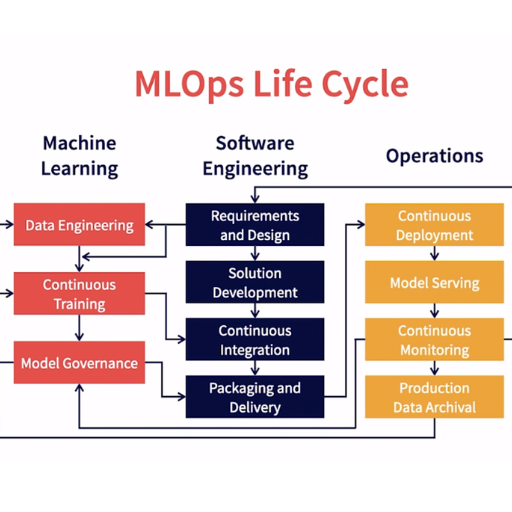
MLOps enhances collaboration between data scientists and operations teams, ensuring smoother workflows and faster time to production. With automation of processes like model retraining, data validation, and versioning, the need for manual work, and the chance of errors, is minimized. This also improves inter project consistency and scalability while enabling efficient model performance tracking and proactive handling of problems like data drift. As a result, machine learning systems become more efficient, reliable, and sustainable.
Streamlining model development and training
The most important aspect of simplifying model development and training is centered around the use of sophisticated tools and organized workflows. I focus on automating mundane activities like hyperparameter tuning and data preprocessing to minimize time expenditure and errors. Moreover, I utilize collaborative platforms that provide version control and facilitate effortless experimentation tracking for transparency and reproducibility. Integration of feedback from production models helps me make performance improvements and continuously align them with changing business objectives.
Enhancing Model Deployment and Monitoring
Failing to deploy and monitor the models accurately can lead to a steady decline in the efficiency and effectiveness of machine learning models in production environments. The deployment phase of models directly impacts the execution environment, be it a cloud environment, edge device, or on-premise system, as these systems have varying models for deployment. The use of containerized microservices which can be built using Docker or Kubernetes plays a crucial role in optimizing the deployment phase.
To ensure the operational maintenance of the system, automation for the tracking of critical activities such as accuracy, latency, and resource consumption must be integrated at the system level. With real-time monitoring, system automated tools can detect data drift, concept drift, and prediction anomaly behavior, allowing the team to act with proactive measures. Optimizing the process can be done by intertwining CI/CD pipelines, which would help in ensuring seamless updates and low downtimes. Furthermore, continuous retraining of models with relevant data is needed and thus, mark the feedback loops to aid in maintaining performance over time.
Ensuring continuous integration and delivery in ML projects
Effective practices for continuous integration and continuous deployment (CI/CD) should be established first so that ML projects will be successful. In every automation step, start with the training pipeline that includes data collection, data cleansing, feature extraction, and model evaluation. Reproducibility and consistency in results are facilitated by the automation processes. Transparency and versioning are important for change tracking; therefore, a version control system should be implemented for both code and data. Monitoring catches bugs and inefficiencies early, so it is important to perform unit testing for code, integration testing for the pipeline, and performance testing for the models.
Next, the alignment of development and production environments can be simplified using containerization tools such as Docker. Using Kubernetes as an orchestration platform allows for automatic deployment and scaling of ML models, which increases productivity. Reliability is maintained by monitoring the performance of the deployed models for drifts and errors; actively working to mitigate those issues will ensure reliability. The incorporation of new data into retraining workflows is vital for real-world model performance, so feedback loops ensure that models do not remain stagnant.
As can be seen, the more robust the CI/CD system is, the fewer errors there are, the faster iterations occur, and the greater the improvement within the ML workflows.
What tools and platforms are available for MLOps?
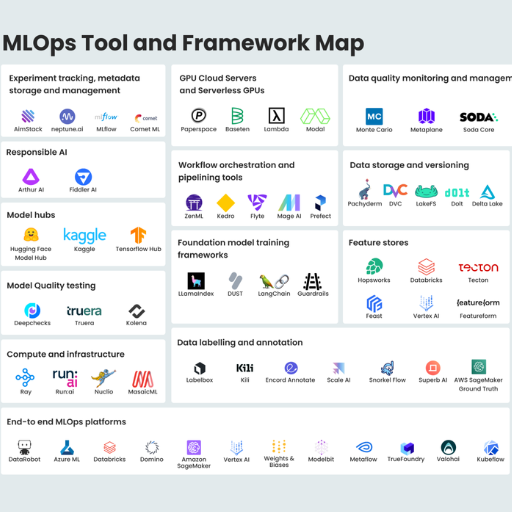
From managing collaboration through version control, to orchestration and model deployment, there are several tools and platforms available for MLOps. DVC and Git are usually the go-to platforms when it comes to version control, while GitHub Actions, GitLab CI, and Jenkins are efficient for managing CI/CD pipelines. When it comes to deploying models, AWS SageMaker, Kubernetes, and Docker are the most widely used technologies. For monitoring model performance and identifying issues, Prometheus, Grafana, and MLFlow are powerful platforms. On the other hand, Azure ML, Google Vertex AI, and Kubeflow offer integrated platforms best suited for effective MLOps workflows. Usually, the right choice of tools can differ from organization to organization due to singular infrastructural and operational requirements.
Top MLOps tools for model management and versioning
A select few of the top tools for managing and versioning MLOps models work seamlessly and are exceptionally versatile. For example, DVC (Data Version Control) is a well-known candidate that provides Git-like functionalities designed specifically for datasets and machine learning model management, which facilitates teamwork. In addition, MLFlow represents a one-stop shop for solutions to experiment tracking, model management, and model deployment, making it highly useful across multiple workflows. Finally, Weights & Biases has developed a strong reputation for its rich functionality in experiment tracking and model versioning and easy integration with many frameworks and platforms. These tools mentioned are known for their ease of use and scaling with changing project requirements, which makes them highly preferred.
Cloud-based MLOps solutions: AWS, Azure, and Google Cloud
AWS, Azure, and Google Cloud head the cloud service market and offer integrated MLOps services for automating the entire workflow of machine learning.
AWS (Amazon Web Services): Businesses can effectively automate the entire machine learning lifecycle from data processing to model training to deployment with SageMaker’s MLOps tools. Automated pipelines along with feature stores and model monitoring ensure that an automated workflow is maintained throughout the machine learning lifecycle. AWS’s scalability and rich ecosystem make it ideal for enterprises needing extensive machine learning resources.
Azure: With integrated DevOps, Azure’s automated ML feature enables AI-powered model training and facilitates agile operations for managing the lifecycle of machine learning models. Additional integrations with other services offer seamless automation while enhancing security and business standards compliance. Solutions with prebuilt integration and security features are strategically favorable for enterprise-ready businesses and Microsoft does that best with Azure.
Google Cloud: By using Open-source frameworks, range of tools and features which are available on Vertex AI platform are augmented. Autonomously operated multi-purpose machine learning functionalities like model monitoring and AI Pipelines along with simple model training and comparison set Vertex AI apart. Flexibility enhancement for researchers and developers is an additional feature of Vertex AI.
These cloud service providers have distinct features tailored towards specific businesses, which enables them to serve a diverse machine learning clientele.
The selection hinges on an organization’s emphasis on ecosystem fit, security needs, or usability.
Choosing the right MLOps platform for your needs
The selection of an appropriate MLOps platform is determined by multiple aspects specific to your organization. To begin, determine how the platform will fit into your current technology to check if it will integrate easily. AWS SageMaker, Google Vertex AI, and Microsoft Azure Machine Learning are examples of platforms that are likely to support a multitude of integrations and can be used in various settings.
Another very important aspect is the scalability of the platform. Think about how the platform will accommodate your growth in data processing and model deployment. Scalable platforms are beneficial in coping with changing workloads and are essential in emerging machine learning projects. Also, consider the degree of automation provided for mundane chores like preparing data, training models, and supervision.
Data and model security, as well as their compliance, especially in heavily regulated industries, are crucial components that govern the protection of both the information and the models. It becomes imperative with sensitive data to select platforms that have strong security boundaries and governance platforms that can shield such data. Finally, check the platform for ease of use alongside the level of disbursed technical assistance. Major platforms that have friendly dashboards and good support services improve the productivity of the teams who need to work with the system.
With these pointers in hand, you can derive the most suitable MLOps platform which would enable your organization to achieve set goals vis-a-vis operational efficiency in machine learning processes.
References
Frequently Asked Questions (FAQ)
Q: What are the key benefits of MLOps pipeline automation?
A: The key benefits of MLOps pipeline automation include improved efficiency in model development and deployment, enhanced collaboration between data scientists and ML engineers, faster time-to-market for ML models, increased reproducibility of experiments, and better model performance monitoring. By automating the ML pipeline, teams can focus on innovation rather than repetitive tasks, leading to more robust and scalable machine learning systems.
Q: How does MLOps differ from traditional DevOps?
A: While MLOps builds upon DevOps principles, it specifically addresses the unique challenges of machine learning projects. MLOps focuses on the entire lifecycle of ML models, including data management, model training, and continuous monitoring of model performance in production. DevOps vs MLOps: DevOps primarily deals with software development and IT operations, whereas MLOps extends these practices to include data science workflows, model versioning, and the complexities of deploying and maintaining ML models in production environments.
Q: What are the essential components of an MLOps pipeline?
A: The essential components of an MLOps pipeline include data ingestion and preparation, feature engineering, model training and tuning, model evaluation, model versioning and registry, deployment automation, monitoring and logging, and feedback loops for continuous improvement. These components work together to create an end-to-end MLOps platform that supports the entire lifecycle of machine learning models, from development to production.
Q: What is MLOps Level 1, and how does it differ from MLOps Level 2?
A: MLOps Level 1 typically involves basic automation of the ML pipeline, including continuous integration and deployment of ML models. At this level, teams start to implement version control for code and data, and automate model training jobs. MLOps Level 2 builds upon Level 1 by introducing more advanced practices such as continuous training, A/B testing, and automated model performance monitoring. Level 2 also focuses on creating more sophisticated feedback loops and implementing MLOps best practices across the organization.
Q: How does MLOps pipeline automation improve model training and inference?
A: MLOps pipeline automation improves model training and inference by standardizing and streamlining the process of developing, deploying, and maintaining machine learning models. It enables data scientists to easily experiment with different algorithms and hyperparameters, while ensuring that successful models can be quickly moved to production. Automated pipelines also facilitate continuous training, allowing models to be updated with new data and retrained regularly, thus maintaining optimal performance over time.
Q: What are the core MLOps principles that guide pipeline automation?
A: The core MLOps principles guiding pipeline automation include version control for code, data, and models; continuous integration and delivery of ML systems; automated testing and validation of models; reproducibility of experiments and results; monitoring and logging of model performance in production; and collaboration between data scientists, ML engineers, and operations teams. These principles help ensure that ML projects are scalable, maintainable, and can deliver consistent value in production environments.
Q: Why do organizations need MLOps, and how can it help manage machine learning projects?
A: Organizations need MLOps to effectively manage the complexity and scale of modern machine learning projects. MLOps can help by providing a structured approach to developing, deploying, and maintaining ML models in production. It addresses common challenges such as model drift, reproducibility issues, and the gap between experimental and production environments. By implementing MLOps, organizations can improve collaboration between teams, accelerate the delivery of ML-powered features, and ensure the reliability and performance of their machine learning systems in real-world applications.
Q: What tools and technologies are commonly used in MLOps pipeline automation?
A: Common tools and technologies used in MLOps pipeline automation include version control systems like Git, containerization platforms like Docker, orchestration tools like Kubernetes, CI/CD platforms such as Jenkins or GitLab CI, model registries like MLflow, experiment tracking tools, feature stores, and monitoring solutions. Additionally, cloud platforms often provide integrated MLOps services that combine many of these functionalities. The specific tools used may vary depending on the organization's needs and existing technology stack, but the goal is to create a cohesive end-to-end MLOps platform that supports the entire ML lifecycle.