Unlocking the Potential of Event-Driven Architecture in a Synchronous World
The rapid development of a given software changes its associated system’s operational and architectural frameworks in regards to workload complexity and dynamism. For many uses, synchronous systems continue to be the predominant choice. However, they continue to lack the required degree of responsiveness, flexibility, and scalability when faced with unforeseen circumstances. This is where event-driven architecture (EDA) comes into play. EDA provides a framework that promises greater efficacy and responsiveness to events in real time.
This post will focus on how EDA augments traditional synchronous architectures and the opportunities EDA has to offer. We will define the primary concepts concerning event-driven design, analyze its advantages and constraints, and detail examples where an amalgamation of synchronous and asynchronous approaches, EDA serves powerful results. After reading this post, you will be able to appreciate the advantages of adopting EDA and how it helps organizations navigate uncertainty in a hyperconnected digital ecosystem.
What is Event-Driven Architecture?
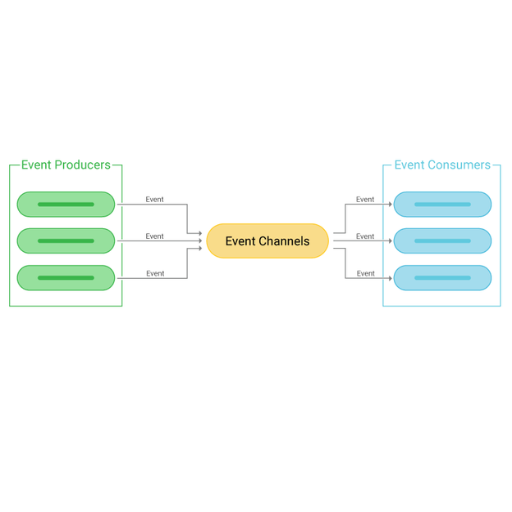
An Event-Driven Architecture (EDA) represents a software design pattern wherein system components communicate by producing and responding to an event. An event refers to a user action or system update that causes a notable change to the system. As opposed to direct component calls in a system, EDA uses event producers and consumers connected by a middleware such as a message broker. This form of communication is loosely coupled and offers more flexibility, scale, and responsiveness which is suitable for dynamic real time data workflows.
Understanding Event-Driven Systems
Event-driven systems are built around the notion of producing, detecting and reacting to an event. Unlike other systems, which directly interact with each other, these components interact with each other through events. With loose coupling comes the benefits of better scalability and more support for real-time processing. Message brokers and other middleware make it possible for event producers and consumers to work independently, which transforms the systems into a dynamic framework fit for modern flexible workflows.
Key Components in Event-Driven Architecture
- Event Producers
An event producer is any entity that generates an event. These can include applications, devices, or services that can detect a state change and emit events accordingly.
- Example Technical Parameters:
- Events format. (e.g., JSON, XML)
- Event size (e.g., may be up to 256 KB for many systems)
- Event rate (e.g., number of events per second)
- Event Consumers
Event consumers are systems or applications that subscribe to and consume the events created by the event producers. They perform specific tasks or activities based on the events received.
- Example Technical Parameters:
- Rate of event consumption. (e.g., throughput in messages per second)
- Latency requirements. (e.g., for real-time applications <100ms)
- Scalability. (e.g., system’s ability to handle concurrent events)
- Event Channels
Event channels act as the link connecting the producers to the consumers. These are usually implemented through message brokers or pub/sub systems. They ensure proper transport of events and offer reliable delivery.
- Example Technical Parameters:
- Message delivery guarantees, e.g., at-least-once, at-most-once, exactly-once
- Supported protocols e.g. MQTT, AMQP, HTTP
- Queue Capacity e.g. capped number of buffered events
- Event Processors
Event processors consume events, perform transformations, or trigger workflows based on the event data. They are critical for value creation from events.
- Example Technical Parameters:
- Processing latency: <50ms for low-latency applications
- Support for intricate workflows (e.g., branching, workflows incorporating merging of multiple sub-workflows)
- Fault tolerance (e.g., recovering from failures)
- Event Storage
Event storage offers a reliable way to keep events for processing, auditing, or replaying later. This is useful for systems that need to analyze data over time.
- Examples of Technical Parameters:
- Retention policy (e.g., keep events for 7 days)
- Storage method (e.g,. object storage, distributed database)
- Maximum event size (e.g., for batch processin, 64MB)
With an understanding of the components and their technical parameters, an architect can build sophisticated, scalable systems that are tailored to specific criteria.
Benefits of Using Event-Driven Models
Based on my understanding, implementing event-driven models comes with many powerful benefits. Component decoupling it allows for easier system flexibility, growth, and responsiveness, leading to improved workloads and scalability. Users are also able to process information in real-time, allowing for immediate reactions to critical events, which is a requirement for modern applications. Since services operate independently, maintenance and updates are easier, reducing the risk of cascading failures. In general, event-driven architectures enable systems to be adaptable and efficient while improving user experience.
How Does Synchronous Event-Driven Architecture Work?
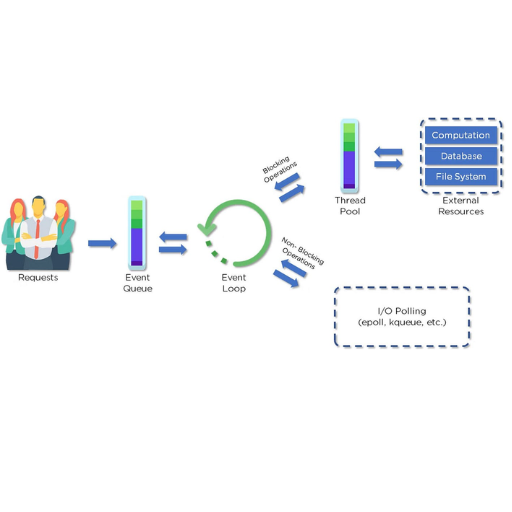
Synchronous event-driven architecture functions on the basis that components interact with one another via direct, synchronous calls. For each event brought up, the sender waits until a response is received from the receiver before moving forward, which guarantees a smooth and instant transfer of information. This is best for immediate feedback circumstances, like user interaction or critical transaction processing. However, this is dependent on a tightly coupled service, which can become an issue as the system gets more complex. This architecture must be designed and managed efficiently for optimal results, utilizing this structure.
Defining Synchronous vs. Asynchronous Communication
The exchange of information that requires both the sender and the receiver to be available at the same window of time is known as synchronous communication. When both parties are available at the same time, interactions in real time occur. HTTP requests, database queries, and remote procedure calls all qualify as synchronous communication. It works best with scenarios that require quick response times. Due to the nature of,” synchronous communication”, it guarantees a response without delay.
Key parameters of synchronous communication:
- Latency: Low relating to network availability and speed.
- Dependency: A high attribute since, without response, the entire procedure is stalled from moving forward.
- Real Time: Chat simulators, financial transactions, user verification, or authentication.
Receiving a message forwarded to a specific phone number without prior consent qualifies as asynchronous communication. The term refers to being allowed to continue with other tasks while a response or action is expected without any immediate expectation. Fused with the notion of batch processing, asynchronous communication is employed in flexible systems that require scaling.
Key parameters include:
- Dependancy: The absence of a reply does not hinder the operations of other peripherals, which can continue to work on other tasks.
- Latency: Because these answers are flexible and not directly on demand, there is some variability in timing.
- Suggested Usages: Background tasks, high systems that need to be fault-tolerant or augment throughput.
These notes help plan and design the proper components within the organization. The models streamlining each communication model pave a straight path towards imprioving productivity.
Implementing Synchronous Event-Driven Systems
In synchronous event-driven systems, the components are organized around strong coupling. One component issues a request, and the other component responds. While this setup is beneficial for cases where immediate feedback or a guaranteed processing order is needed, it requires additional engineering work.
Key Design Principles:
- Event Flow: Guarantee that events will be executed sequentially, one after the other.
- Blocking Operations: A process halts until a response is returned which means that there is further dependency on the time it takes to get the response.
Technical Parameters:
- Timeout Settings: How long the system will wait for a response before giving up (normally 2-10 seconds).
- Throughput: Provided the network and the processors spend a lot of time idle, this is usually measured in Requests Per Second (RPS).
- Latency: Active waiting will need to be done to ensure there are no bottlenecks on the network (typical optimal latency is less than 100ms).
- Error Handling: What should the system do when timeouts or errors occur? Retry, fallback, user notification, etc.
Use Cases:
Synchronous systems such as payment processing, user authentication or any other system that requires confirmation tend to work smoothly. On the other side, these systems can get hard to scale when dealing with high loads and real-time responses are required. Properly balancing the load and allocation resources is key to ensuring these systems remain robust.
With proper assessment of the parameters in relation to business requirements, synchronous event-driven systems, such as those used in avionics, multi-channel video surveillance, and robotic systems, can achieve the accurate level of reliability and precision needed for critical applications.
Use Cases for Synchronous Event Processing
As I see them, synchronous event processing handles cases where two-way communication and immediate reaction is crucial rather well. Such items include payment systems where transactions are authenticated right away, live auctions where every bid taken must be displayed on the screen right away,” and authentication workflows that also involve real-time user validation. These scenarios all require very low latency and a highly available environment. In the cited instances, user experience is seamless.
Some key technical parameters to be observed are very low latency time of less than 100 milliseconds for speed in reactivity, high availability solutions with 99.99% uptime for the always on nature of the systems, and support for parallel growth to efficiently control request volume. Proper monitoring tools to manage throughput and response time to different conditions also help maintain the desired performance level.
How is Kafka Used in Event-Driven Architecture?
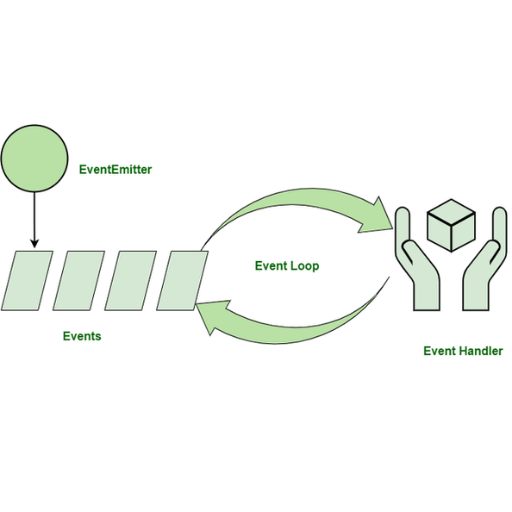
In the context of establishing a modern application, Kafka is trying to change the perception of event processing by defining a new standard of performance. It acts as a distributed messaging system in which the producer and consumer are completely separated, which allows each one to operate separately, enhancing overall system performance. This means that different services can communicate efficiently because a producer can send an event to a topic, and a consumer can subscribe to that topic at any time. Moreover, Kafka guarantees endurance and fault tolerance so that even if the system is under considerable strain, there is no loss of event data while throughput remains hig, which enables efficient processing of large volumes of events. This characteristic makes Kafka most suited for the development of scalable, dependable, asynchronous systems within an event-driven architecture.
Understanding Apache Kafka as an Event Broker
Kafka aids in the event-driven architecture of a system by serving as an event broker, which allows real-time communication between producers and consumers. Using a publish-subscribe architecture, producers write events into topics and consumers subscribe to those topics to process the events. With Kafka’s distributed architecture, it will ensure high availability, fault tolerance, and durability, which event-driven architectures require in large-scale data pipelines and system reliability.
Role of Kafka in Event Streams
Kafka fulfills a vital role in an event streams ecosystem as a fault-tolerant, high throughput, real time data flow processing platform between systems. Personally, I consider Kafka as the heart of our event driven architecture. He provides the complete communication framework between producers and consumers, which allows scaling and provides fault tolerance. Because of its distributed nature, we can process large amounts of data with low latency and high throughput.
About the technical parameters, these are some of the main points that I consider when working with Kafka:
- Throughput: the number of messages per second per topic that is handled by Kafka is in the magnitude of tens of thousands
- Replication Factor: set to not less than 3 to maintain the availability of data and the fault tolerance configured policy
- Partitioning: improves scalability as it divides a topic into multiple partitions, which can be processed in parallel.
- Retention policy: allows specifying the duration or storage limit for which messages are retained, thus providing flexibility for diverse scenarios.
- Latency: Optimized scenarios can achieve sub-millisecond latency for message delivery.
- Message Durability: achieved through configuration of acks and durable settings
With these parameters, Kafka becomes much more flexible and performant in building reliable data pipelines and real-time applications.
Benefits of Using Kafka for Scalability
Kafka, as a business, encrypts data in real time and is highly scalable. First, its distributed architecture yields seamless horizontal scaling by simply adding more brokers to the cluster. More brokers added means better throughput, even with increased data volume. Second, Kafka’s partitioning ability allows workload distribution across multiple nodes, further improving resource utilization. Finally, Kafka guarantees system reliability through its robust fault tolerance and replication capabilities, even through high hardware load or failures, making it ideal for real-time data stream processing.
What are the Patterns in Event-Driven Architecture?
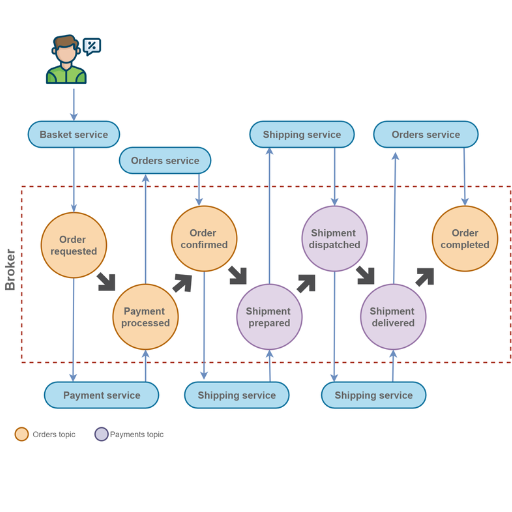
- Event Sourcing
This pattern is concerned with capturing the state changes of an application as a log made up of immutable events. In contrast to persisting the current state, event sourcing enables you to reconstruct the state at any point in time by replaying the events, providing excellent audit capabilities and flexibility.
- CQRS (Command Query Responsibility Segregation)
CQRS separates the state modification (commands) and the state query (reads). This creates possibilities for optimized architectures for both write-dominant and read-dominant scenarios, which increases scalability and performance.
- Publisher-Subscriber Model
Publishers generate events and send them to a central broker who dynamically sends them to interested subscribers. The decoupling of components enables each to evolve in an independent manner while continuing to retain communication.
- Event Stream Processing
This pattern continuously processes streams of events, enabling real-time analytics and actionable insights. It is often employed in events such as fraud detection or personalized recommendations.
- Event-Carried State Transfer
Rather than having consumers query sources for context, events themselves include state information required by consumers, reducing latency and dependency.
These patterns are designed to work with asynchronous messaging, with each pattern being the better choice for certain contexts within event-driven architectures.
Common Architectural Patterns
Like any other architecture pattern, they are best described with their use cases. As such, focus on the practical use case and its associated technical parameters. Provided are short descriptions along with the parameters of some patterns discussed above.
- Event Notification
Question: In which way does event notification reduce system coupling?
Answer: Event notification decouples both producers and consumers by using asynchronous communication. Producers simply publish events and consumers take actions on them independently.
Technical Parameters:
- Latency tolerance (e.g., milliseconds to seconds)
- Middleware throughput capacity (e.g., messages per second)
- Maximum number of event consumers
- Event-Carried State Transfer
Question: In which way does this pattern improve performance?
Answer: Consumers are able to reduce latency and dependency by performing processes without the need to fetch external information multiple times, when state data is embedded within the event.
Technical Parameters:
- Event size (e.g., kilobytes to megabytes)
- Consumer processing speed
- Storage limits for event histories
- Event Sourcing
Question: Why is event sourcing beneficial for audit trails?
Answer: While auditing and debugging, having a complete history of events with immutable records is ideal, and event sourcing provides just that.
Technical Parameters:
- Storage requirements for event logs
- Retrieval performance for historical data
- Consistency mechanisms for event order
The above details help with establishing boundaries concerning the various architectural patterns of event-driven systems regarding performance, scalability and simplicity.
Best Practices for Loose Coupling
In software architecture, the ‘loose coupling’ principle provides component independence, allowing systems to be more scalable, maintainable, and adaptable. Here’s a list of the best practices to achieve loose coupling with their corresponding technical parameters:
- Utilize Interfaces and Abstraction:
Tightly defined interfaces and APIs ensure that any changes within a module do not impact the other components. This makes it easier to replace, update, or remove individual parts of the system.
- Technical Parameter: Ensure there are proper API specifications at every governance level through versioning and backward compatibility.
- Event-Driven Communication:
Asynchronous communication methods like message queues (RabbitMQ, Kafka) can be used to separate consumers from producers. They do not have to function in real-time and can operate at their own pace.
Technical Parameters:
- Measure the latency and throughput of the message queues.
- Set up retries and dead-letter queues to allow for easier non-consumed message handling.
- Dependency Management:
Avoid close integration through the use of dependency injection frameworks. This provides the possibility to change the supplied dependencies without changing the primary logic.
- Technical Parameter: Employ dependency management within lightweight frameworks such as Spring.
- Data Ownership and Sharing
For every service, design systems that require each service to own its data and share it only via API gateways instead of direct database sharing. This is to avoid exposing shared databases that have a high coupling concern at the data layer.
- Technical Parameter: Track API interaction and responsiveness to baseline metrics for performance value delivery and implement adequate throttle constraints.
- Decentralized Governance
Empower teams to govern their microservices however they want to do without approval on all levels, creating faster systems-wide updates. This eliminates limitations to deploying more agile and efficient workflows.
- Technical Parameter: Allocate service level objectives (SLO) for every microservice in place to enhance control on metrics of expressed targeted operational outcomes.
These approaches, alongside the outlined technical constraints, give you the ability to build systems that,t without any further intervention, adapt and evolve on a shifting requirement landscape while delivering optimised performance.
Designing for Fault Tolerance
The design of systems with fault tolerance tries to incorporate elegance in the way resilience can be added to a system so that its seamless functioning is not disrupted even when certain components are disabled or non-functional. For me, building resilience entails redundancy by ensuring critical components have backups that can manage failures. Also, workloads during outages are automatically shifted using failover mechanisms. Additionally, I also utilize circuit breakers to stop failures from cascading while workloads are spread to multiple nodes to avert single points of failure. Regularly testing the system using chaos engineering aids in early identification of weaknesses and ensures reliability and robustness.
How to Address Error Handling in Event-Driven Systems?
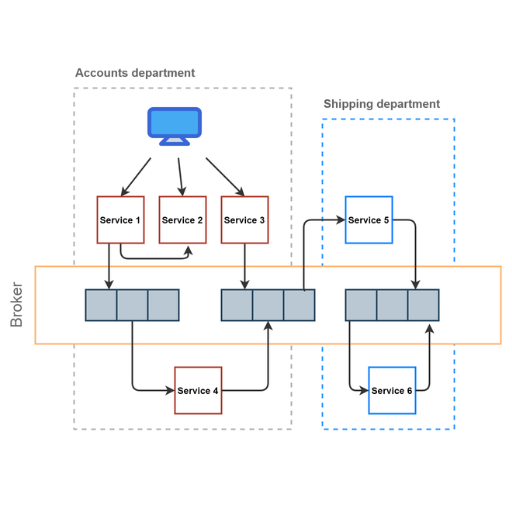
Event-driven systems offer sophisticated methods for fault handling and rely on the systematic breakdown of a system into recoverable and non-recoverable parts to guarantee stability. Start by mitigating non-recoverable faults through implementing retry strategies paired with exponential backoff for transient errors. Capture messages that are undeliverable using a dead letter queue (DLQ). Add later debug and resolution, enabling capture messaging by DLQs through the later addition of idempotency in event processing to avoid retries. Efficiency and accuracy in the identification of issues and their diagnosis rely on clear-cut logging and monitoring. Finally, structure the system to apply appropriate fallback mechanisms without overusing them on non-recoverable errors.
Challenges in Error Handling
- Recognizing Bound Messages
Picking up and analyzing bound messages or undeliverable messages poses a problem. A possible answer is employing Dead Letter Queues (DLQs).
- Parameter: Ensure that DLQ meta-information includes, at a minimum, outlined metadata such as error codes, message ID, and timestamp for better traceability.
- Handling Duplicate Events
Avoidance of duplicate actions within retries is critical. The incorporation of idempotency during event processing solves the problem.
- Parameter: Each event should be accompanied by a unique request ID or transaction ID to validate and trace the processing status.
- Structured Logging
Robust logging is required for resolving multifaceted problems. Clear logs enhance pattern identification and root cause analysis.
- Parameter: Logs must be in JSON format with designated fields such as timestamp, event type, and severity level of the event.
- Differentiating Error Types
Targeted fallback systems necessitate division between errors that are recoverable as well as errors not recoverable.
- Parameters:
- Categorize errors via code range ascertainable (i.e., 4xx client errors, 5xx server errors).
- Define policies for retry, such as: exponentially increase intervals for transient error, but do not permit retries for fatal errors.
- Scalable Monitoring Systems
Effective monitoring tools are needed for real-time diagnosis and detection of issues.
- Parameters:
- Establish thresholds for latency, 500ms, for example, in API responses.
- Supervise error rates where a 1% threshold will trigger an alarm.
When challenges with defined parameters are taken care of, effective systems engineering along with defined technical parameters fosters further refinement for these systems to become truly resilient and adaptive to errors.
Strategies for Robust Event Processing
Developing solid plans with key technical details is fundamental for effective event processing. Here are the short answers along with the reasonable technical suggestions:
- Prioritizing of queue-based event retrieval/handling
Use message queues (RabbitMQ, Kafka) for asynchronous event storage and retrieval systems.
- Specifications:
- Maximum queue size (e.g., 10,000 messages so as not to overload).
- Timeout for message acknowledgment (e.g., 30 seconds so as not to stall processing).
- Enable Idempotent Processing
Duplicate event proofs should be adverse outside said construct.
- Parameters:
- Given the nature of Idempotent processing sans duplicates, unique event identifiers (UUIDs for each given event) would be warranted.
- Event expiration policies would also be necessary (auto-expiring given identifiers, e.g., after 24 hours).
- Employ Backpressure Mechanisms
Regulate the system and event flood control during system busy periods to avoid over- or under-system load.
- Parameters:
- Maximum concurrent event processing limit per Node(50 events per node).
- Rate limiting thresholds (100 requests per second).
- Define Autonomous Error Handling And Retry Policies
Instances of automated corrective actions with fallback mechanisms and prompt recompute processes are highly encouraged during failure detection events.
- Parameters:
- Intervals of repeated activity through exponential backoff (2 seconds, max of 5 times).
- Breaker trippoints(50% when the failure rate exceeds breaker tripping).
- Performance monitoring, optimization, and adjustment checklists.
Real-time analytics tools should be used for event processing performance monitoring on the system through put checks.
- Parameters:
- Event processing latency target threshold, e.g., 500ms per event, and increased processing speed. In other words, throughput metrics include measurement units such as ‘1,000 events per second capacity’.
By executing these event strategies with well-optimized parameters, the event processing system becomes more robust, proficient, and capable of enduring performance challenges under numerous changes.
Ensuring Fault Tolerance in Event-Driven Architecture
In an event-driven architecture, replication, failover, and distributed processing are the three strategies that ensure fault tolerance. I avoid data silos and service outages by replicating important data and services on multiple nodes. My failover strategies also automatically reroute *workloads* to healthy nodes if any failures occur. Having workload silos on multiple nodes also ensures that the architecture remains resilient against any single point of failure. In addition, my monitoring and alerting systems enable swift issue identification and resolution, which *guarantees* architectural robustness under varying conditions.
References
- Event Driven Architecture Sync: A Friendly Guide - A detailed explanation of how event-driven architecture works in synchronous systems.
- Advantages of the Event-Driven Architecture Pattern - Discusses the benefits and practical applications of event-driven architecture.
- The Complete Guide to Event-Driven Architecture - A comprehensive guide on the principles and implementation of event-driven systems.
Frequently Asked Questions (FAQ)
Q: What is event-driven architecture and how does it differ from traditional architecture?
A: Event-driven architecture is a design pattern in which the flow of program execution is determined by events such as user actions, sensor outputs, or messages from other programs. Unlike traditional architectures that rely on synchronous communication, event-driven systems are often asynchronous, allowing for more decoupled and flexible components. This design is commonly used in distributed systems to enhance scalability and real-time data processing.
Q: How do microservices benefit from an event-driven architecture?
A: Microservices benefit from event-driven architecture by being able to decouple services, allowing each service to operate independently. This decoupling is facilitated through asynchronous events, where event producers and event consumers communicate without waiting for a direct response, enhancing scalability and resilience in a microservices architecture.
Q: What are the key components of an event-driven microservices architecture?
A: The key components of an event-driven microservices architecture include event producers, which generate events; event consumers, which process those events; an event bus or streaming platform to transport events; and an event store to persist events for future reference. These components work together to enable asynchronous event-driven communication and processing.
Q: How does an event-driven architecture handle synchronous and asynchronous communication?
A: An event-driven architecture can handle both synchronous and asynchronous communication, although it primarily relies on asynchronous event processing. Synchronous event-driven scenarios may occur when immediate feedback is necessary, but overall, the architecture is designed to operate asynchronously to allow for non-blocking communication and increased system responsiveness.
Q: What role does an event store play in maintaining data consistency?
A: An event store plays a crucial role in maintaining data consistency by acting as a persistent log of all events that have occurred within the system. This allows services to reconstruct their state from the event history and ensures that data remains consistent across distributed systems, even in the face of failures or updates to new services.
Q: Why is an asynchronous event-driven architecture preferred for real-time data processing?
A: An asynchronous event-driven architecture is preferred for real-time data processing because it enables non-blocking operations, allowing systems to handle high volumes of data efficiently. By processing events as they arrive without waiting for a response, systems can provide timely insights and actions, which is critical for real-time applications.
Q: How does event-driven architecture support scalability in distributed systems?
A: Event-driven architecture supports scalability in distributed systems by decoupling components, allowing them to be scaled independently based on demand. This flexibility ensures that the system can handle varying loads efficiently, as event consumers can be added or removed without affecting event producers. Stream processing and distributed event streaming platforms further enhance this scalability.
Q: What challenges might arise when implementing event-driven microservices architecture at scale?
A: Implementing event-driven microservices architecture at scale can present challenges such as ensuring data consistency, managing complex event flows, and handling potential performance bottlenecks. Additionally, designing an efficient event bus and dealing with eventual consistency can require sophisticated strategies to ensure seamless operation and integration of new services.
Q: How is a streaming platform commonly used in event-driven architecture?
A: A streaming platform is commonly used in event-driven architecture to provide a reliable and scalable way to transport and process events in real-time. It enables event producers to publish events and event consumers to subscribe to them, facilitating continuous data flow and stream processing across the system, which is essential for maintaining high performance and scalability.